
SEO-специалисты отмечают, что разные сервисы могут показывать разные позиции сайта по одним и тем же запросам. В одном инструменте сайт находится в топ-3, в другом — уже на 7-й позиции, а в Яндекс Вебмастере отображается средняя позиция между ними. Из-за этого у бизнеса и SEO-команд регулярно возникает вопрос: где правда и каким данным доверять?
В этой статье расставим точки над «i»: как сегодня устроен сбор поисковых данных, почему выдача постоянно меняется и почему расхождения между сервисами — это не ошибка, а особенность современного поиска.
Поисковая выдача больше не выглядит одинаково для всех
Чтобы понять, почему данные расходятся, важно сначала посмотреть на то, как изменилась сама поисковая выдача. Если раньше SERP был относительно простым — 1–2 рекламных объявления и органическая выдача — то сегодня поиск выглядит совершенно иначе. В выдаче появились:
- AI-ответы;
- динамические места;
- визарды;
- товарные блоки;
- персонализация;
- A/B-тесты поисковой системы.
Причём поисковая выдача меняется постоянно. Кроме того, на результаты влияют:
- история поиска;
- cookies;
- fingerprint;
- персонализация;
- эксперименты Яндекса.
«Поисковая выдача представляет собой алгоритм машинного обучения, который ранжирует сайты и дообучается на поведении пользователей» – Артём Сирота, менеджер качества данных SEOWORK
Именно поэтому два пользователя могут увидеть разную выдачу даже в один и тот же момент времени.
Почему SEO-сервисам пришлось менять подход к сбору данных
Ситуация на рынке серьёзно изменилась после обновлений антифрод-систем Яндекса. В декабре 2025 года наша команда столкнулась с большим количеством капчи и блокировок при сборе данных из поисковой выдачи. Это привело к ограничениям скорости сбора, ограничениям объёма данных и нестабильности парсинга. В результате команда начала искать альтернативные источники данных и перешла на Yandex Search API.
Почему выбор пал на Yandex Search API
На то есть несколько причин:
- Это официальный инструмент получения поисковой выдачи.
- Можно напрямую взаимодействовать с Яндекс по качеству данных
- Он позволяет избежать блокировок и получать более стабильные данные.
- Масштабируемость: Благодаря отсутствию этих лимитов сервис может значительно увеличивать объёмы собираемых данных.
- Гибкость под запросы клиентов: Это позволяет системе «расти в плане сборов» и более эффективно подстраиваться под индивидуальные объёмы и потребности конкретных клиентов.
Но позиции всё равно отличаются – почему?
Даже после перехода на официальный API расхождения между сервисами полностью не исчезли. Причина — разные методы подсчёта данных в форматах HTML и XML в Yandex Search API.
На первый взгляд может показаться, что это просто разные технические способы получения данных. Но на практике разница намного глубже.
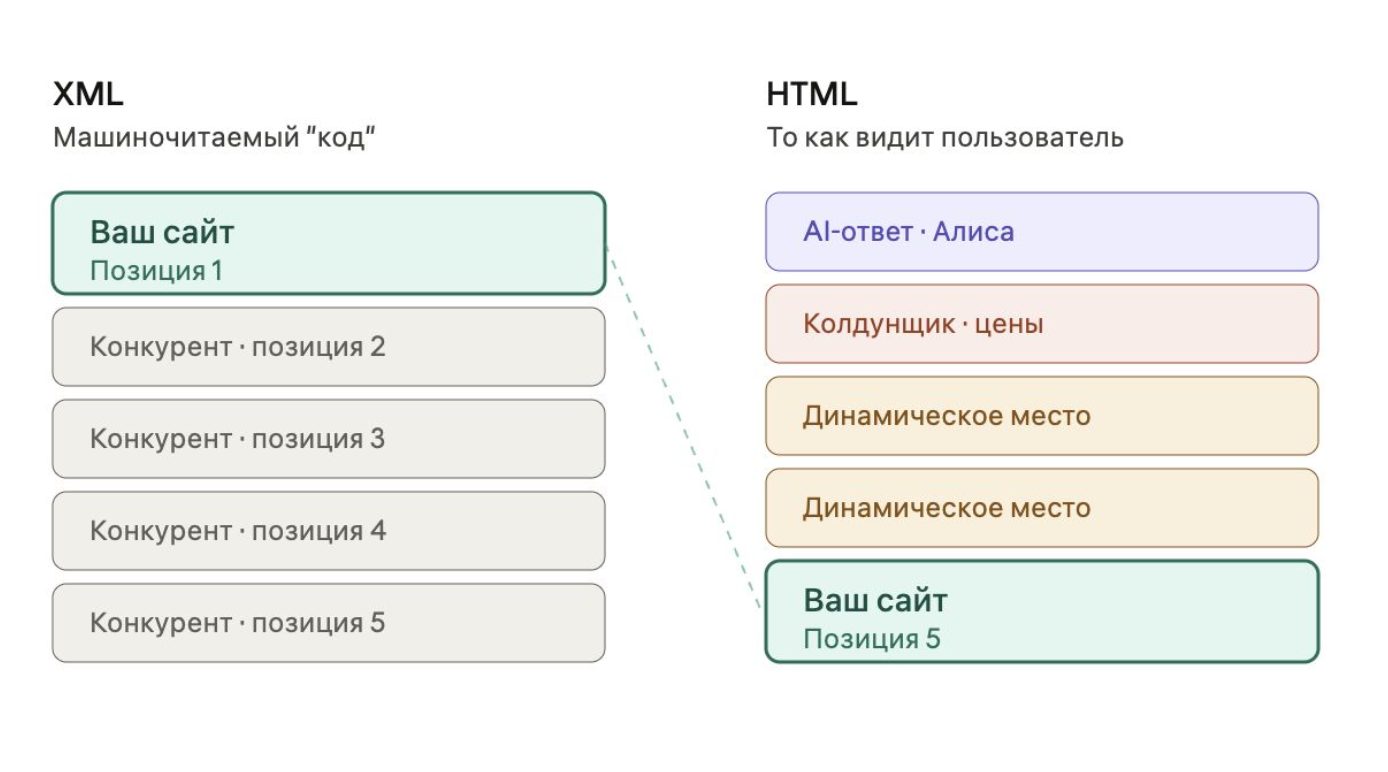
XML показывает только органическую выдачу и представляет собой машиночитаемую структуру данных.
HTML показывает выдачу так, как её видит пользователь:
- AI-блоки;
- динамические места;
- визарды;
- дополнительные элементы SERP.
При этом HTML значительно сложнее поддерживать. Именно поэтому позиции могут отличаться очень сильно.
О разнице XML, HTML и Yandex Search API рекомендуем почитать наше большое исследование в предыдущей статье →
Почему нельзя ориентироваться только на Яндекс Вебмастер
Логичный вопрос, если Яндекс Вебмастер показывает данные самой поисковой системы, почему бы не использовать только его? Плюсы — реальный пользовательский трафик. Но у этого подхода есть ограничения:
- в Вебмастере нет данных по конкурентам.
- данные хранятся только две недели.
«Мы не можем ответить для себя на вопрос: по каким запросам вообще мы можем продвигаться лучше, чем наши конкуренты – это упущение» – Артём Сирота, менеджер качества данных SEOWORK
Поэтому для полноценной SEO-аналитики мы используем внешний сбор данных.
Как SEOWORK следит за качеством данных
«Мы одни из первых на рынке реагируем на изменения в поисковой выдаче и работе официальных поисковых сервисов» – Ксения Меньшикова, аналитик данных SEOWORK
За эталон сравнения в компании используют Яндекс Вебмастер. При анализе команда сравнивает:
- позиции конкретного запроса;
- конкретную дату;
- HTML и XML одновременно;
- устройства;
- регионы.
Интересный факт: даже если максимально всё повторить, выдача всё равно будет несколько меняться. Мы проводили собственный эксперимент и выявили, что выдача будет волатильна даже при синхронных ежечасных сборов с нескольких устройств и максимальном повторении условий в течение недели. Поэтому наша платформа ориентируется не только на отдельные позиции, но и на тренды.
Кроме того, за качество данных в SEOWORK отвечает специализированный отдел Data Quality, который использует многоуровневую систему мониторинга для обеспечения точности аналитики. Процесс проверки разделен на глобальный мониторинг и детальный анализ конкретных проектов.
Глобальный мониторинг и выявление аномалий
Команда Data Quality использует статистические методы для автоматического обнаружения отклонений в данных. Мониторинг ведется по трем основным направлениям:
- Внутренние системы: отслеживание сбоев в работе собственных алгоритмов и интеграций.
- Со стороны поиска: фиксация изменений в верстке поисковой выдачи или случаев, когда поисковик перестает отдавать определенные данные.
- Со стороны клиента: контроль доступности сайта в выдаче (например, если сайт пропал, а конкуренты остались, проблема на стороне ресурса клиента).
Благодаря этим инструментам наша команда одной из первых реагирует на обновлении элементов в поиске Яндекс и Google.
Методология проверки на уровне проектов
Для оценки качества данных в конкретных проектах аналитики используют следующие методы:
- Сравнение с эталоном: в качестве «золотого стандарта» используются официальные данные Яндекс Вебмастера и Google Search Console.
- Синхронные тесты: для минимизации погрешности запускаются одновременные сборы данных в форматах HTML и XML.
- Точечное сравнение: анализируются позиции конкретных запросов в один и тот же день с учетом региона и типа устройства.
- Анализ трендов и близости ТОПов: специалисты проверяют, насколько динамика позиций в сервисе совпадает с данными Вебмастера, особенно для запросов, стабильно находящихся в ТОП-10.
Алгоритм определения вида проблем для проектов
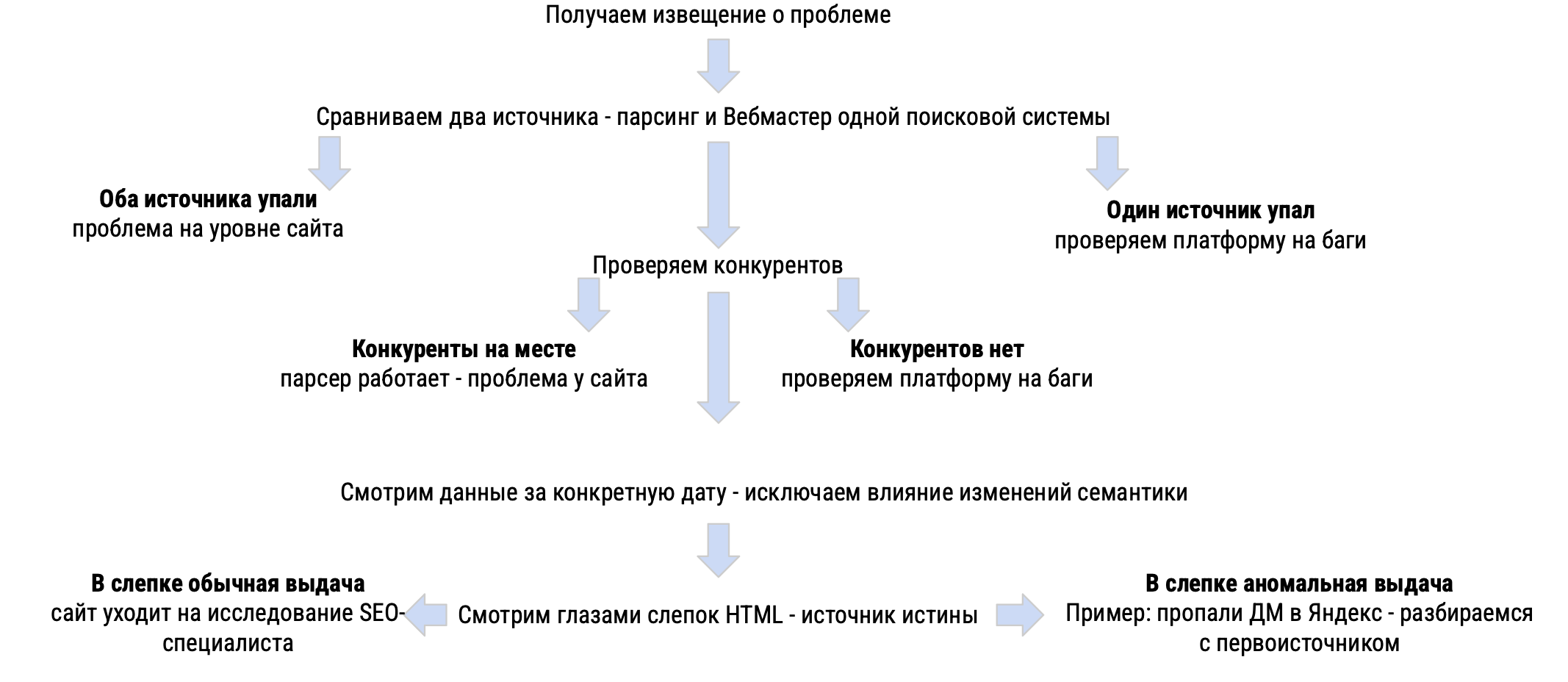
При обнаружении просадок или расхождений применяется строгий алгоритм:
- Сравнение источников: если данные парсинга и Вебмастера упали одновременно — проблема на уровне сайта.
- Проверка конкурентов: если парсер работает исправно и конкуренты на месте, а сайт клиента упал — это SEO-проблема сайта.
- Исключение влияния семантики: проверяется, не менялось ли семантическое ядро в дату аномалии.
- Источник истины — HTML-слепок: аналитики «глазами» проверяют сохраненную копию поисковой выдачи (слепок), чтобы убедиться, что система корректно считала позицию и не возникло ли в выдаче аномальных блоков (например, исчезновения динамических мест).
Получается:
- Если в слепке видна аномальная выдача (например, пропали динамические места), команда начинает разбираться с первоисточником (поисковиком).
- Если выдача в слепке обычная, а сайта на нужных местах нет, проект передается на исследование SEO-специалисту.
Кейсы решения проблем
Кейс 1: Услуги для бизнеса (коммерческое ядро)
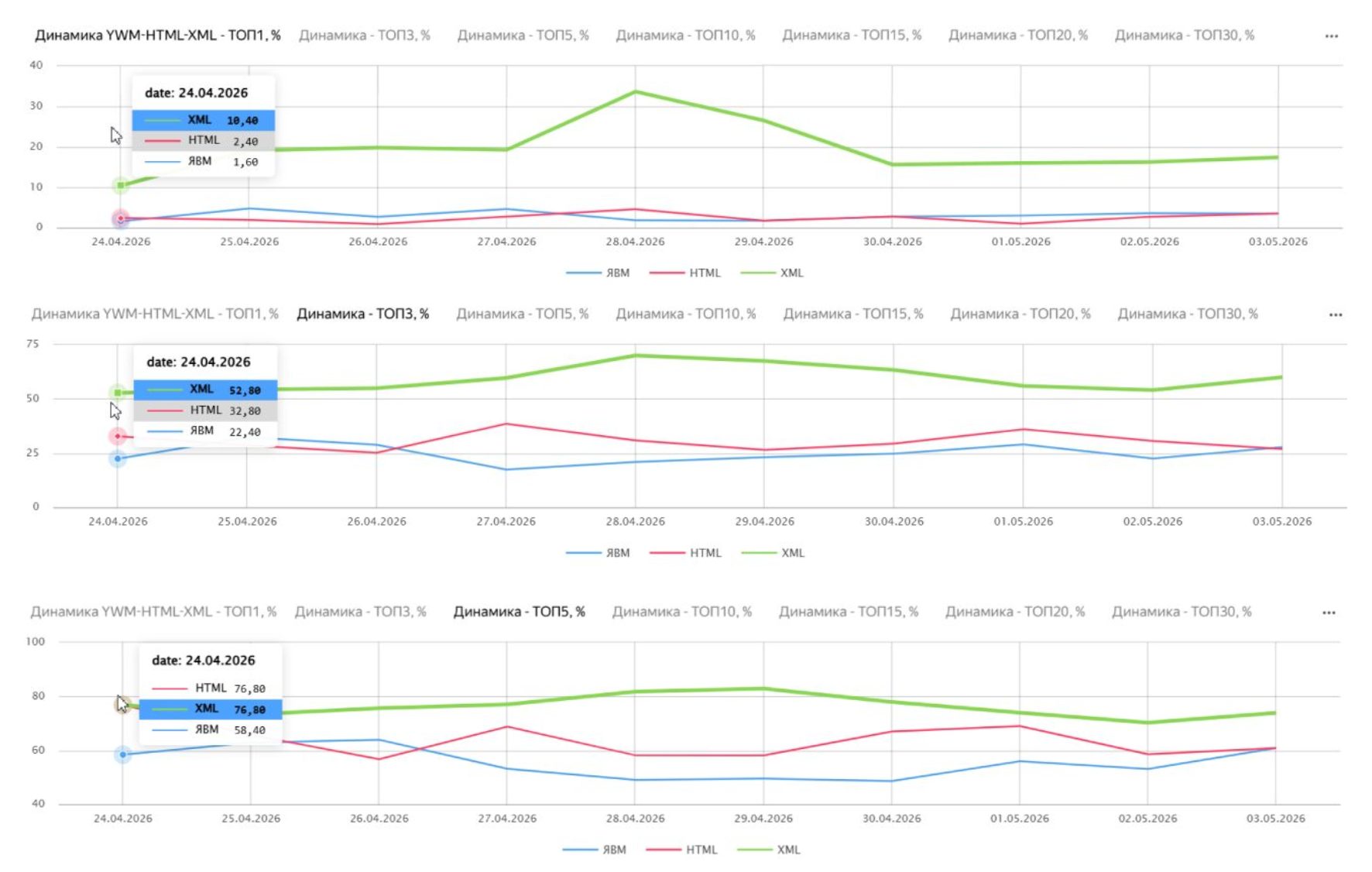
В этом кейсе рассматривался проект с коммерческими запросами в сфере B2B. Основные выводы анализа:
- Разрыв между XML и реальностью: Данные формата XML показывали неоправданно позитивную картину (высокие позиции), в то время как HTML-сбор и Яндекс Вебмастер давали более приземленные и схожие между собой результаты,.
- Близость к эталону: Графики подтвердили, что красная линия (HTML) и синяя (Вебмастер) сохраняют общий тренд и находятся ближе друг к другу, чем XML.
- Бизнес-вывод: Ксения подчеркнула, что специалисту важно решить: показывать ли заказчику «красивые», но неполные цифры из XML или использовать HTML, чтобы видеть реальную выдачу со всеми блоками и находить точки роста.
Вывод: Для коммерческих проектов в сфере услуг рекомендуется использовать формат HTML, так как он минимизирует разницу с официальными данными Яндекса и дает более правдивую картину для аналитики и выполнения KPI
Кейс 2: Статейник (информационное ядро)
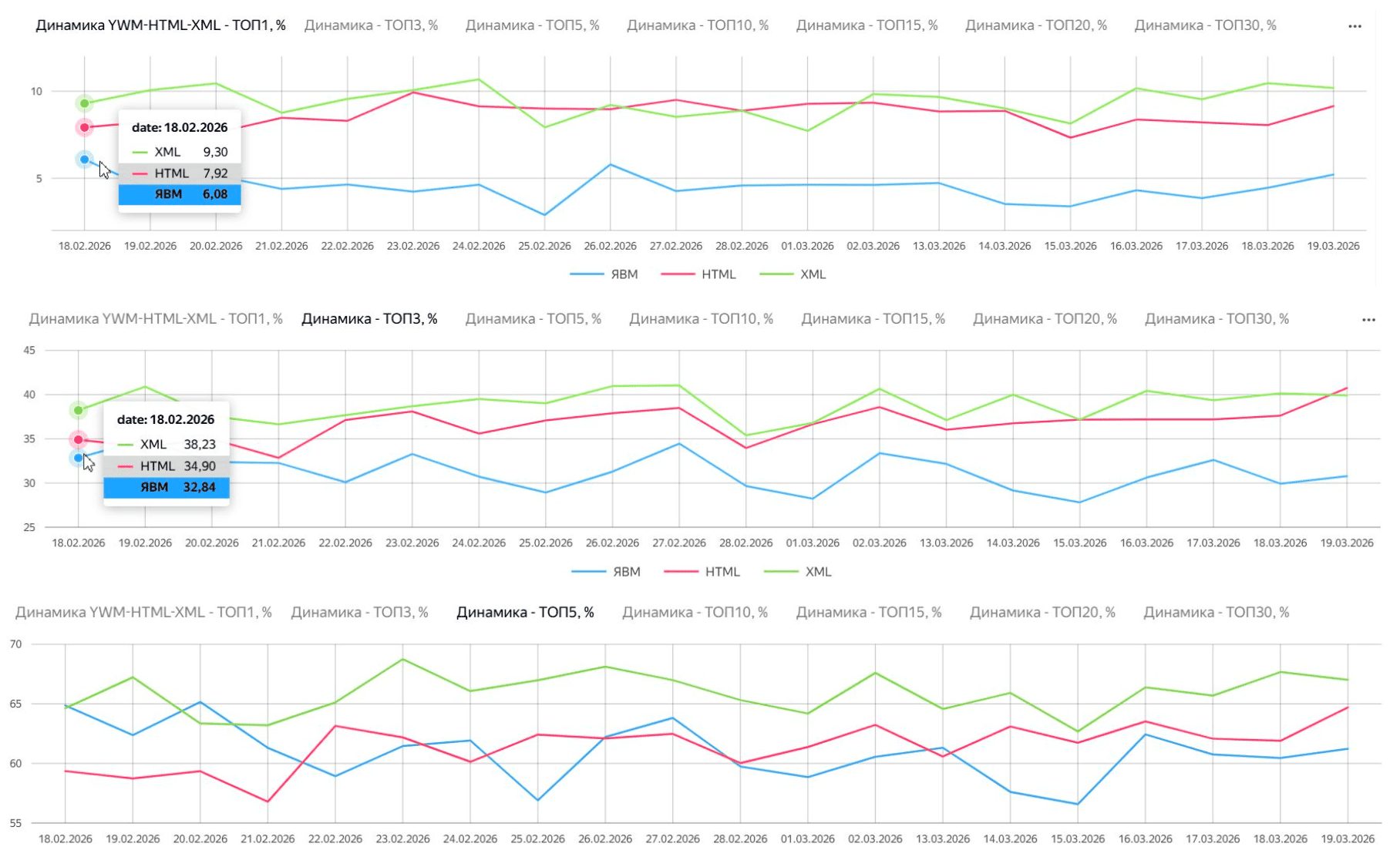
Кейс посвящен информационному проекту, где анализировалось поведение данных для статей.
- Синхронность форматов: Для информационных запросов данные HTML и XML часто идут близко друг к другу в рамках ТОПа выдачи.
- Совпадение трендов: Несмотря на то, что в отдельные дни позиции могли различаться (например, HTML показывал позиции чуть ниже, но был ближе к Вебмастеру), общие тренды на графиках полностью совпадали.
- Стабильность: В инфо-выдаче меньше динамических коммерческих блоков, поэтому данные разных систем здесь более согласованы.
Вывод: Для информационных проектов данные разных форматов сбора (HTML и XML) обычно согласованы, и специалисту достаточно следить за общим вектором развития проекта, который подтверждается всеми источниками.
Кейс 3: E-commerce (коммерческое ядро и динамические места)
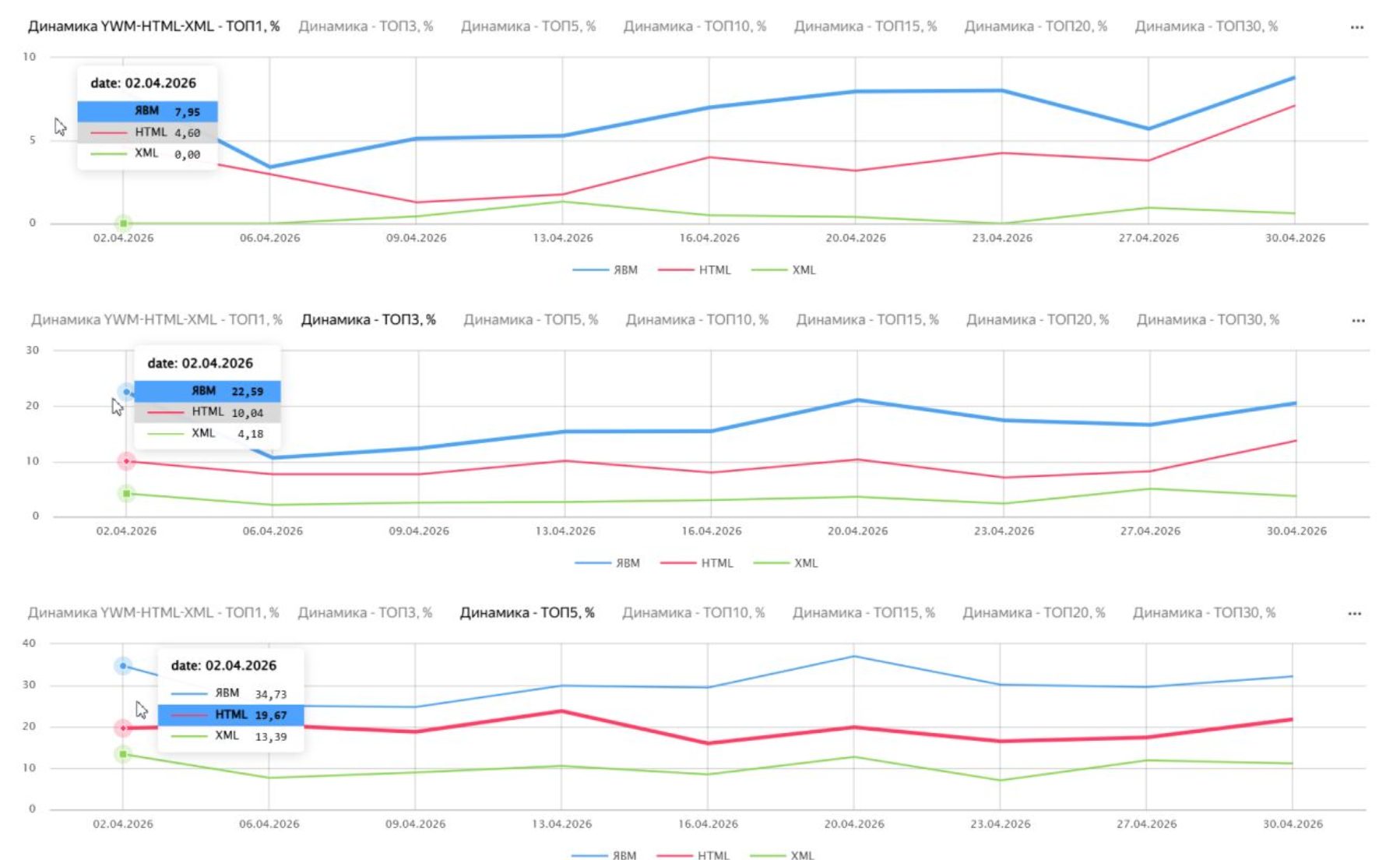
Самый сложный кейс, в котором клиент использовал динамические места (ДМ).
- Влияние аукциона: Позиция сайта в выдаче Яндекса может резко меняться в зависимости от того, выиграл ли ваш сайт или сайт конкурента аукцион за динамическое место в конкретный момент сбора,.
- Расхождения в моменте: Например, если конкурент включил ДМ, сайт может «отъехать» назад в HTML-выдаче, при этом XML (не учитывающий эти блоки) покажет более высокую, но менее правдивую позицию.
- Усреднение данных: Ксения показала, что если в конкретный день данные HTML и Вебмастера могут сильно расходиться (например, 4-я позиция против 8-й), то при анализе за месяц данные всех форматов усредняются и стремятся к единому значению.
- Рекомендация: При анализе E-commerce проектов необходимо всегда смотреть на тренд и учитывать факторы ДМ и персонализации.
Вывод: Для сложных e-commerce проектов необходимо использовать HTML-сбор, чтобы учитывать фактор динамических мест, и ориентироваться на месячные тренды, а не на точечные замеры в конкретный день
Главный вывод
«Все эти методы позволяют нам лишь приблизиться к тому, как бы себя вёл пользователь» – Артём Сирота, менеджер по качеству данных SEOWORK
Главная правда заключается в том, что ни один сервис не покажет единственно верную цифру для всех пользователей сразу. Однако использование продвинутых методов сбора и регулярный мониторинг качества позволяют минимизировать эти расхождения и принимать обоснованные решения для роста KPI вашего проекта.
Качественные данные – это большая ответственность, ведь на их основе прокладывается будущее бизнеса. Эту ответственность и затраты берём на себя мы – ваш SEOWORK.

