
Долгое время поисковая аналитика строилась на простой логике: поисковая выдача — это список ссылок. Замерили позиции, определили долю в Топ-10, отслеживаем динамику. Эта модель работала, пока выдача действительно была списком ссылок. Но!
В 2024–2025 годах Яндекс сильно эволюционировал как поисковик. Выдача превратилась в сложную экосистему. В ней переплелись органические результаты, товарные блоки, Динамические места (ДМ) и генеративные ответы (Алиса). Одновременно с этим Яндекс значительно усилил защиту выдачи от классического парсинга, сделав старые методы сбора данных нежизнеспособными.
Основным источником данных для SEO-сервисов стал Yandex Search API. Причем данные можно получать в XML и HTML-форматах. Чем они отличаются мы подробно рассказали в этой статье.
Команда SEOWORK выбрала HTML-формат. И это не просто смена технологии — это отказ от упрощенного XML в пользу реального слепка выдачи. Этот технологический переход привел к тому, что метрики видимости у ряда наших пользователей скорректировались в худшую сторону.
В январе наш отдел Data Quality запустил исследование на больших данных, чтобы наглядно показать, что новые данные не ошибочны. «Падение» графиков при смене алгоритма — это нормально и не повод для паники, а диагностика скрытых проблем, открывающая новые точки роста.
Результатами наблюдений и выводами делимся ниже.
Иллюзия первого места
Наша команда Data Quality провела масштабное тестирование XML и HTML форматов на сотнях тысяч запросов из высококонкурентных e-com ниш. Съемы данных проводились ежечасно в течение продолжительного периода. Задача была простой: проверить стабильность, полноту и воспроизводимость данных. При сопоставлении данных обнаружили два критических ограничения.
Аномальная волатильность
При ежечасных замерах одних и тех же запросов XML-выдачу буквально «штормит» – позиции доменов ротируются без очевидной причины. Строить надежную аналитику на такой нестабильной базе невозможно.
Скачки позиций в XML:
| asus | XML | |||||
| 12:00 | 13:00 | 14:00 | 15:00 | 16:00 | 17:00 | |
| asus.com | 1 | 1 | 1 | 1 | 1 | 1 |
| asus-store.ru | 3 | 2 | 3 | 4 | 2 | 4 |
| ru.wikipedia.org | 2 | 7 | 2 | 2 | 7 | 2 |
| dns-shop.ru | 4 | 3 | 6 | 6 | 4 | 5 |
| kns.ru | 6 | 4 | 5 | 5 | 3 | 6 |
| cifrus.ru | 5 | 5 | 4 | 7 | 6 | 3 |
| regard.ru | 7 | 6 | 8 | 3 | 5 | 8 |
| onlinetrade.ru | 8 | — | 7 | 8 | 8 | 7 |
| citilink.ru | 9 | 8 | 9 | 9 | 9 | 9 |
| technopark.ru | — | 9 | — | — | — | — |
| 2cent.ru | — | — | — | 0 | 10 | — |
| en.wikipedia.org | 10 | — | 10 | 10 | — | 10 |
| market777.ru | — | 10 | — | — | — | — |
В HTML-слепке картина стабильна:
| asus | HTML | |||||
| domain | 12:00 | 13:00 | 14:00 | 15:00 | 16:00 | 17:00 |
| asus.com | 1 | 1 | 1 | 1 | 1 | 1 |
| asus-store.ru | 2 | 2 | 2 | 2 | 2 | 2 |
| dns-shop.ru | 3 | 4 | 4 | 4 | 3 | 3 |
| technopark.ru | 4 | 3 | 3 | 3 | 4 | 4 |
| kns.ru | 5 | 5 | 5 | 5 | 6 | 6 |
| ru.wikipedia.org | 6 | 6 | 6 | 6 | 5 | 5 |
| regard.ru | 7 | 7 | 7 | 7 | 7 | 7 |
| citilink.ru | 8 | 8 | 8 | 8 | 8 | 9 |
| notik.ru | 10 | 9 | 9 | 9 | 9 | 8 |
| onlinetrade.ru | 9 | 10 | 10 | 10 | 10 | 10 |
| eldorado.ru | 11 | 11 | 11 | 11 | — | — |
| vk.com | 12 | — | — | — | — | — |
Слепота к Динамическим местам
Это ключевая проблема. Формат XML технически не фиксирует рекламные Динамические места, которые Яндекс всё чаще интегрирует в органику.
Что это значит на практике?
XML показывает: «Вы — Топ-1». SEO-отдел отчитывается об успехе. Но в реальности пользователь видит три блока Динамических мест над вашей органической ссылкой.
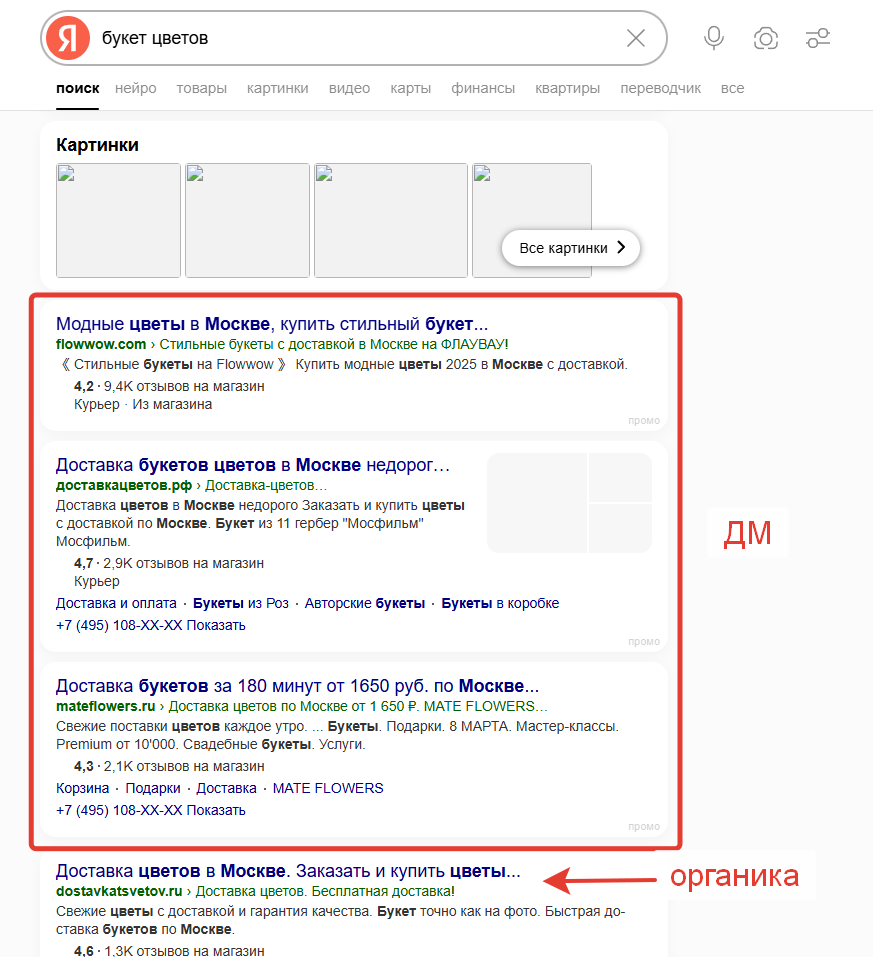
Фактически сайт оказывается на вторых ролях и недополучает трафик. Но в отчёт графики растут.
Возможно, именно поэтому XML-отчеты так любят продавцы накрутки поведенческих факторов. Формат, который слеп к рекламе и подвержен колебаниям — идеальная среда, чтобы отчитываться за фиктивные результаты и продавать клиенту «воздух».
Почему это важно
Если инструмент не учитывает рекламу, не видит спецблоки, подвержен колебаниям, то решения принимаются на искажённых данных. Это влияет на распределение бюджетов и приоритеты SEO-команды
Тест на реальность: сверка с Яндекс.Вебмастером
Наш следующий эксперимент состоял в сопоставлении метрик видимости из трех источников:
- Яндекс.Вебмастер (эталон, то, что фиксирует сам поисковик)
- HTML (SEOWORK)
- XML
Что показало сравнение — XML показывает завышенные значения, которые сильно отличаются от данных Вебмастера.
Средняя позиция
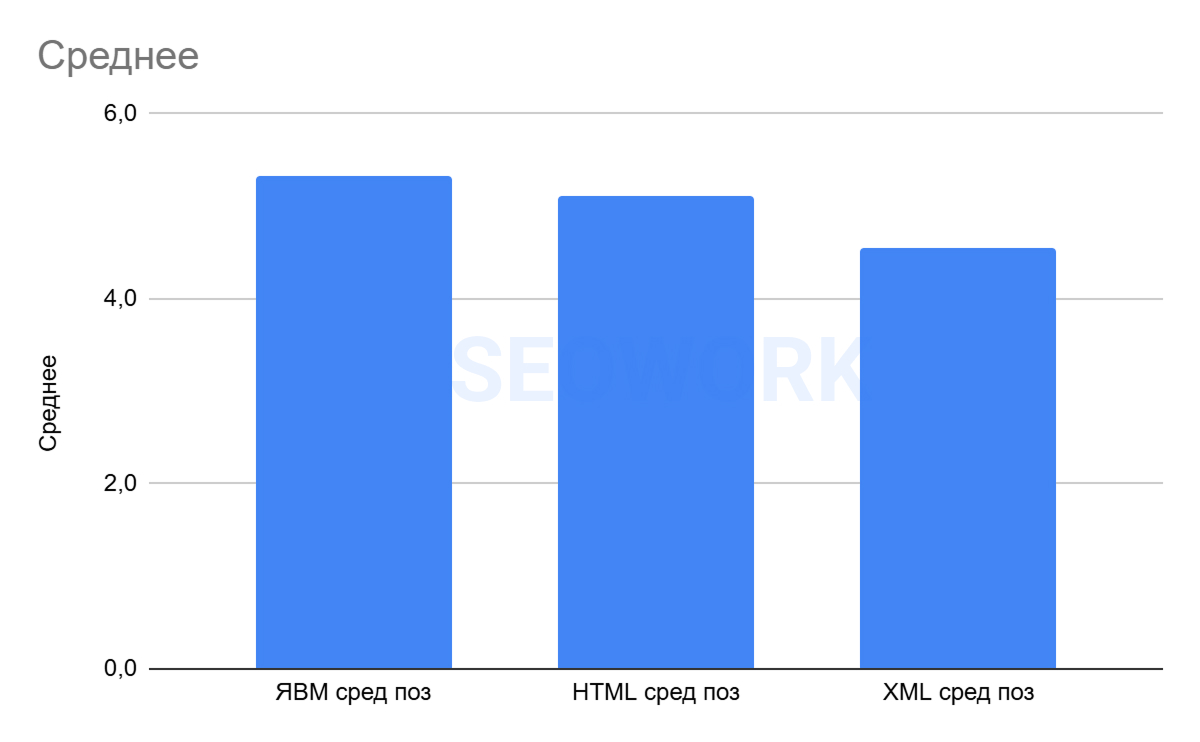
На графике отражено сопоставление данных по средней позиции из Яндекс Вебмастера, HTML (SEOWORK) и XML. Это усреднённые данные за всё время наблюдений
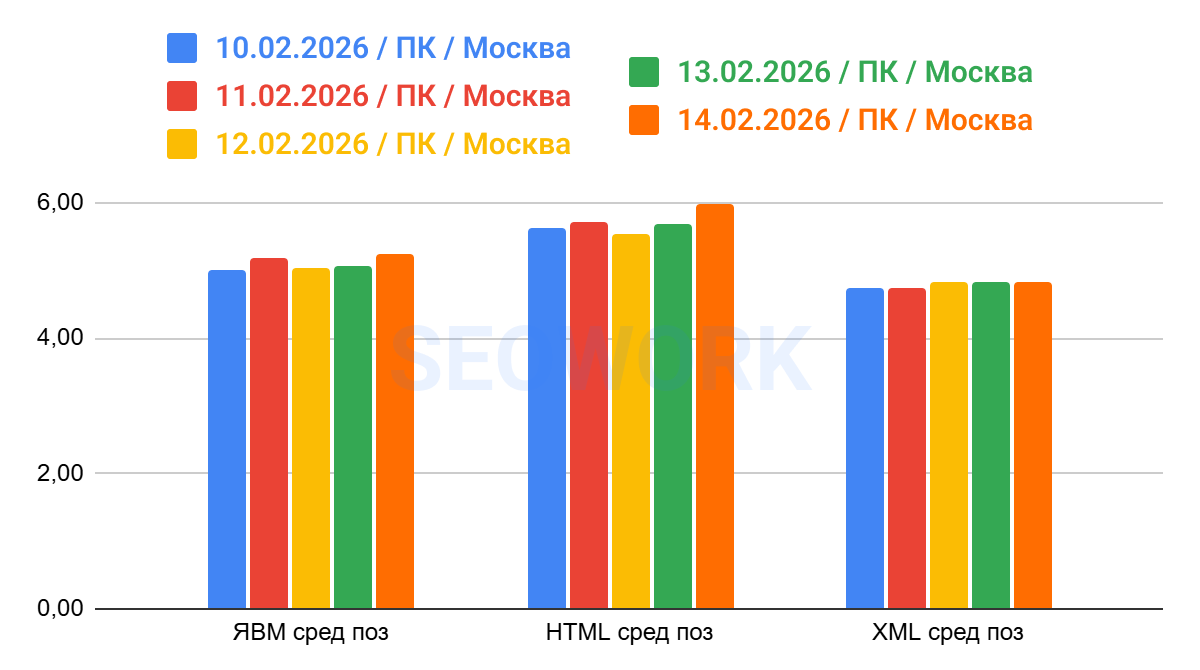
Пример одной недели наблюдений за данными средней позиции по дням для наглядности
Метрики на базе HTML показали высокую близость к Яндекс.Вебмастеру, особенно в критически важных зонах Топ-3 и Топ-5.
Топ-3
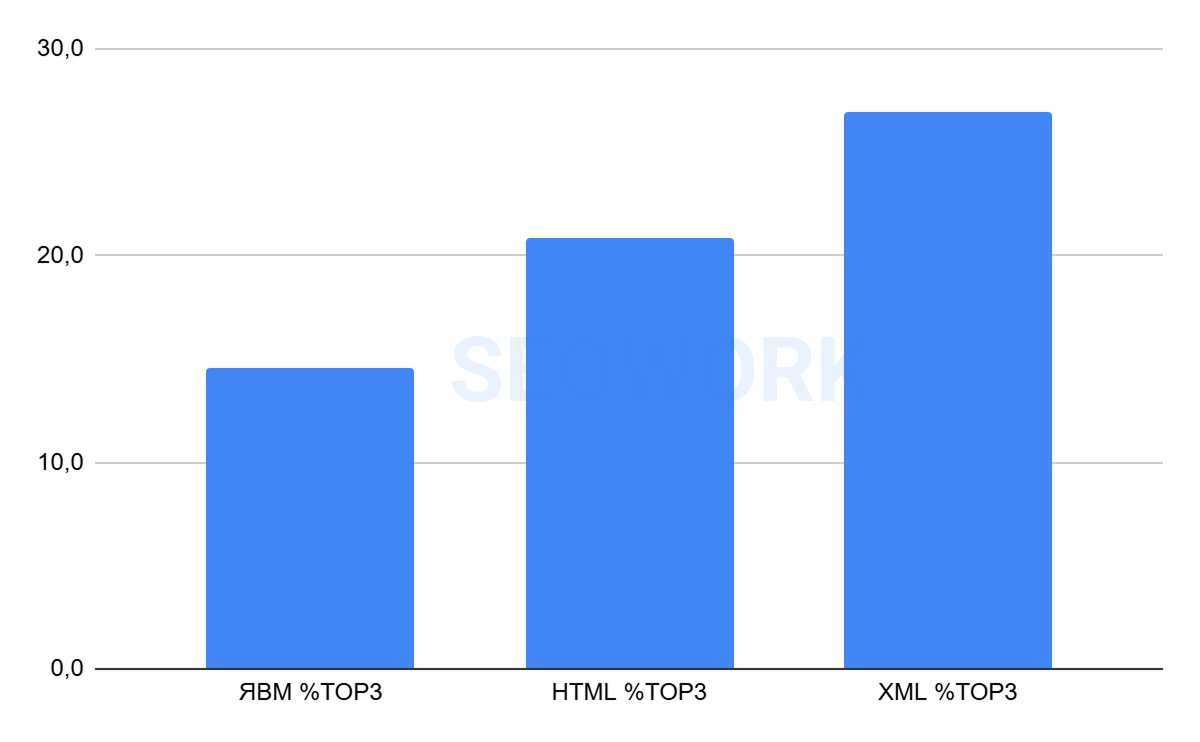
На графике отражено сопоставление данных по Топ-3 из Яндекс Вебмастера, HTML (SEOWORK) и XML. Это усреднённые данные за всё время наблюдений
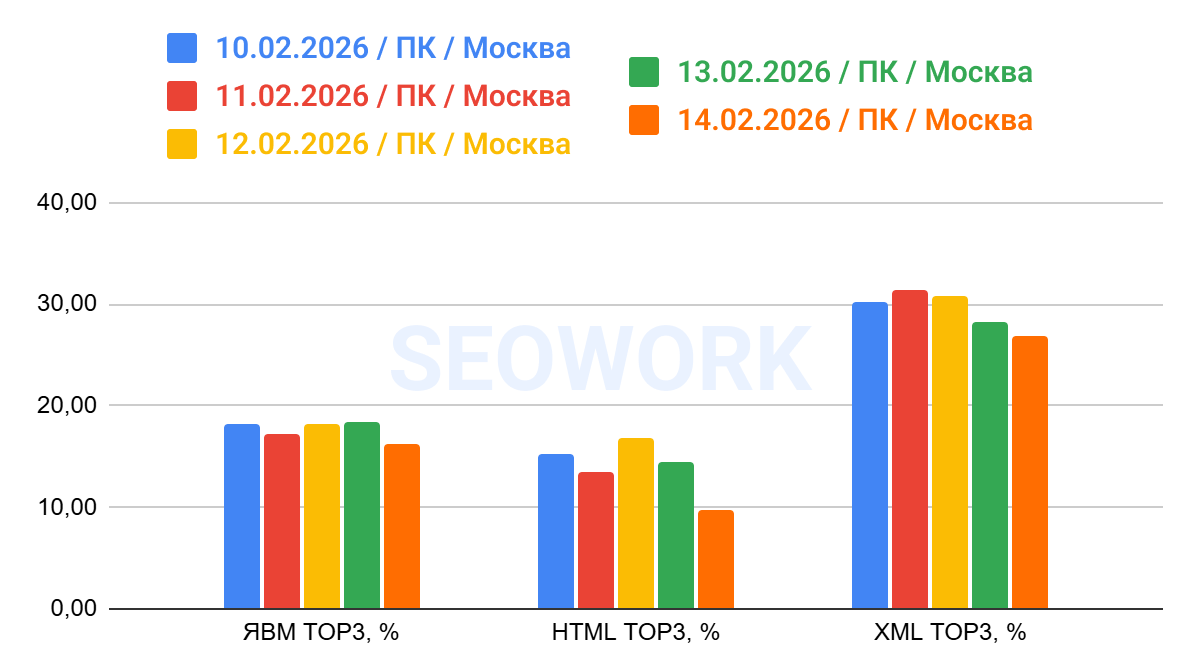
Пример одной недели наблюдений за данными Топ-3 по дням для наглядности
Топ-5
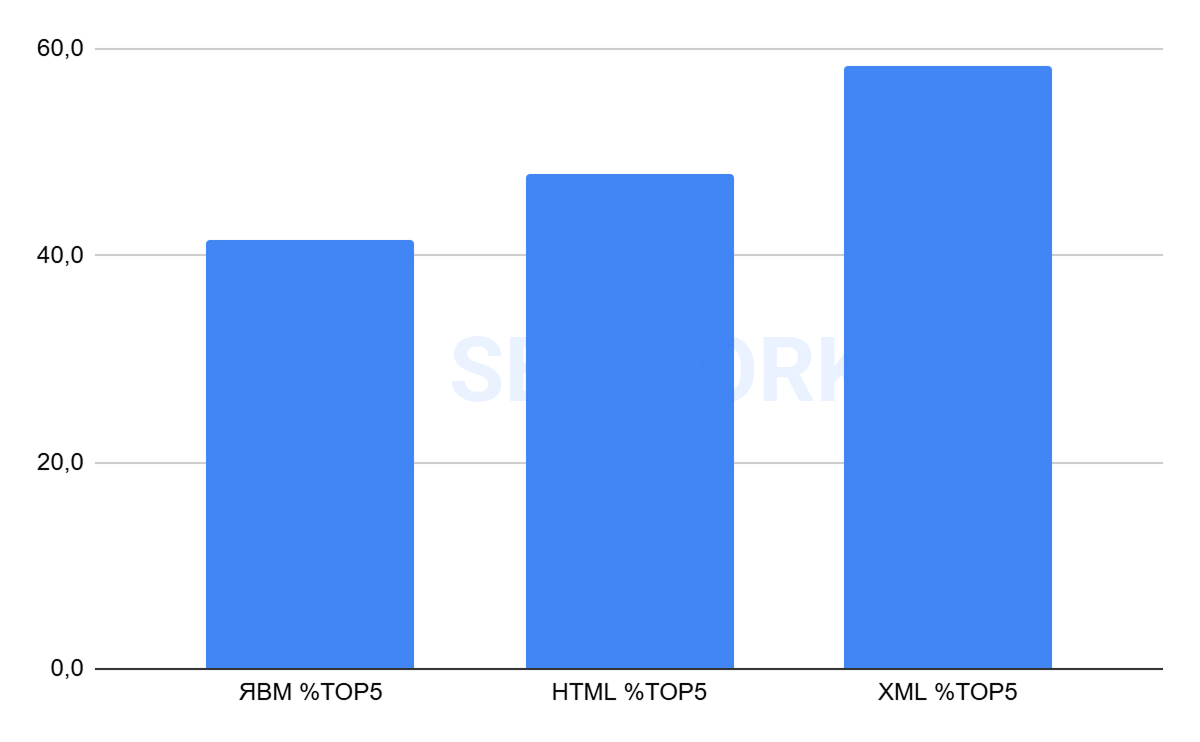
На графике отражено сопоставление данных по Топ-5 из Яндекс Вебмастера, HTML (SEOWORK) и XML. Это усреднённые данные за всё время наблюдений
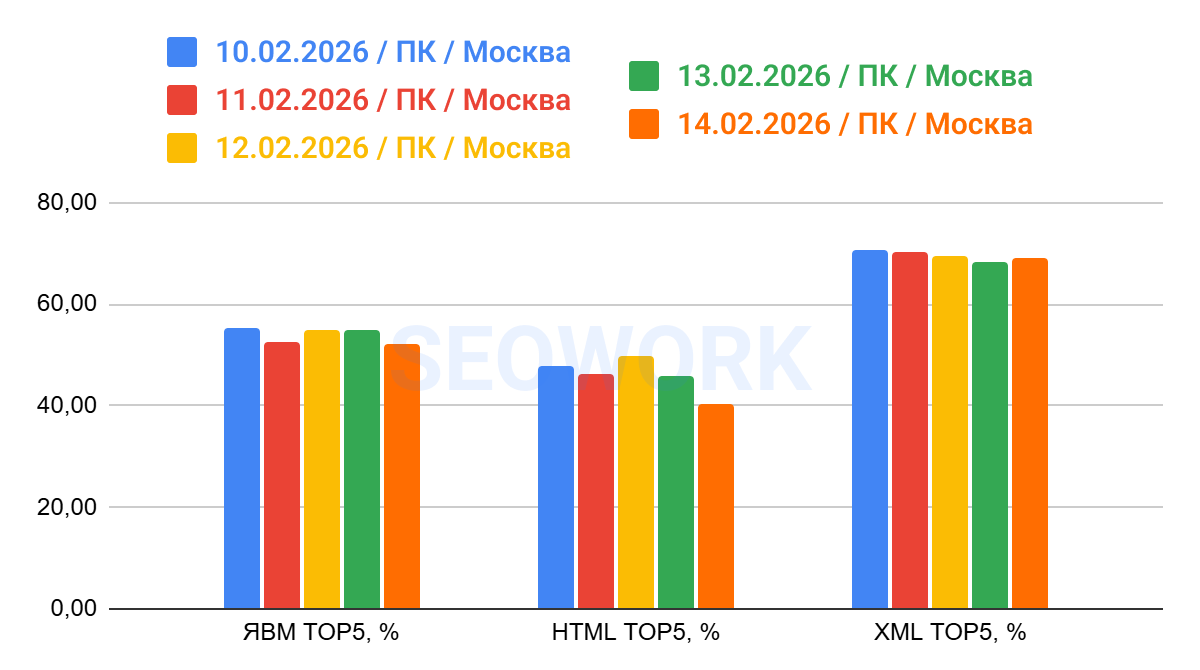
Пример одной недели наблюдений за данными Топ-5 по дням для наглядности
Смена инструмента измерений привела к тому, что показатели % в Топе в платформе SEOWORK снизились. Это можно сравнить с переходом от рулетки к высокоточному лазеру — мы сняли с рынка «розовые очки», чтобы показать реальную картину.
Как работать с «падающими» метриками: инсайты из нашей практики
Снижение метрик при переходе на Search API HTML — это не ухудшение вашей реальной видимости. Это обнаружение слепых зон, которые раньше маскировались несовершенством XML-формата, особенно если вы снимаете позиции в сервисах работающих на XML или пытаетесь найти правду и снимаете позиции в нескольких сервисах сразу или ранее собирали данные через парсинг живой выдачи.
Вот реальные сценарии того, как наши клиенты используют новые данные:
- Выявление каннибализации трафика. Органика «проседает». В HTML-слепке видно: над органикой стабильно стоят Динамические места. Это могут быть конкуренты, или же собственный PPC-отдел компании. В последнем случае SEO-команда может оперировать цифрами и показать, сколько запросов перекрыто рекламой, какая доля кликов уходит в ДМ, обсудить, где стратегии конфликтуют и как их развести. Это разговор уже не на уровне мнений, а на уровне данных.
- Реальная доля в выдаче. Компания считала, что занимаете 45% Топа, а по факту (с учетом всех элементов выдачи и ДМ) лишь 20%. Такая разница — это железный аргумент для защиты новых бюджетов перед топ-менеджментом и разблокировки SEO-задач из бэклога IT-отдела.
Честная картина не всегда комфортна. Но она позволяет управлять.
Следующий уровень сложности — AI-ответы
Появление генеративных ответов (Яндекс.Алиса в поиске) меняет паттерны поведения пользователей:
- пользователь может получить ответ без перехода на сайт
- источники цитируются внутри нейроблока
- формируется новая зона конкуренции — за упоминание
Анализировать присутствие бренда в этих нейроблоках, определять тональность упоминаний и цитируемость источников через XML невозможно в принципе. Работая с HTML-слепками, SEOWORK уже сейчас закладывает архитектуру для глубокой аналитики AI-выдачи. Это уже не вопрос позиций. Это вопрос присутствия в ответе.
Заключение
Адаптация к новому виду выдачи Яндекса — непростой процесс для рынка. Опираться на данные XML или переводить аналитику на HTML-данные – каждая команда делает свой выбор.
Отчеты на основе HTML могут показать просадку и защищать их перед руководством будет сложно. Но для принятия по-настоящему эффективных решений нужна не комфортная иллюзия роста, а прозрачная картина.
И в этом ключе коррекция графиков при переходе на HTML — не сигнал тревоги. Это признак того, что измерение стало точнее.

