
В 2025 году поисковая выдача Яндекса заметно изменилась. Часть изменений была заметна всем пользователям – например, появление ответов Алисы. Ряд нововведений был не так заметен широкой аудитории, но при этом сильно повлиял на SEO-индустрию.
Одним из таких изменений стало усиление защиты поисковой выдачи от ботов, в том числе автоматического парсинга. При этом важно понимать, что защитные механизмы Яндекса — не новое явление. Они существовали и ранее, однако в 2025 году вышли на качественно новый уровень по сложности.
Защитные механизмы Яндекса
Защитные механизмы (антифрод защита) Яндекса направлены на борьбу с манипуляциями поисковой выдачей. Их ключевая задача — исключить влияние накруток и искусственных воздействий, чтобы пользователи получали в выдаче максимально релевантные и безопасные ответы на свои запросы.
В 2025 Яндекс обновил алгоритмы защиты – она строится на искусственном интеллекте. Система анализирует большой массив данных и определяет, кто взаимодействует с системой — реальный пользователь или бот. Для этого используются поведенческие факторы, технические параметры устройств и браузеров, cookie и другие данные. Такой комплексный анализ позволяет выявлять даже сложные схемы автоматизации.
Логика работы защиты строится по превентивному принципу. На первом этапе, ещё до показа контента или обработки запроса, система оценивает вероятность того, что запрос инициирован ботом. Если риск высокий, доступ к «живой» выдаче ограничивается. В случаях, когда автоматическая оценка недостаточно уверенная, Яндекс может применять дополнительную проверку — например, голосовую капчу, которая позволяет подтвердить, что перед системой действительно человек.
По мере усложнения механизмов защиты доступ к сбору данных из «живой» выдачи (парсинг) становился всё дороже и сложнее, а для многих SEO-сервисов — практически недоступным. В результате рынок постепенно сместился в сторону официальных инструментов доступа к данным – Yandex Search API (Yandex AI Studio. Search API).
Yandex Search API (Yandex AI Studio. Search API)
Сегодня подавляющее большинство SEO-сервисов используют Yandex Search API (Yandex AI Studio. Search API) в качестве основного источника данных.
Yandex Search API (Yandex AI Studio. Search API) — сервис, позволяющий отправлять запросы к поисковой базе Яндекса и получать ответы в формате XML или HTML. Сервис предназначен для разработчиков и вебмастеров и помогает организовать поиск по сайту, группе сайтов или интернету, а также дает возможность отслеживать позиции сайтов по поисковым запросам в поисковой выдаче Яндекса
Сервис позволяет получать данные в двух форматах — XML и HTML. Наибольшее распространение получил XML, его чаще всего выбирают SEO-сервисы, считая более удобным решением. Но так ли это на самом деле? В чём различия между двумя форматами, преимущества и недостатки каждого? Давайте разбираться.
Search API XML
Search API XML – XML-файл в кодировке UTF-8, содержащий результаты поиска по заданному поисковому запросу.

XML-формат удобен: быстро, дёшево и стабильно. Но у него есть фундаментальное ограничение — он отражает только позиции сайтов, игнорируя остальные элементы выдачи: ответы Алисы, специальные элементы (например, товарные блоки), рекламу и динамические места. То есть аналитика сервисов, работающих по XML, строится вокруг органической выдачи. Только вот пользователь всё реже видит её в чистом виде.
Наши исследования поисковой выдачи летом 2025г. показали:
- в сфере e-com подавляющее большинство пользователей при поиске товаров сталкиваются в Яндекс с товарными блоками и могут выбрать товар не перебирая варианты на сайтах в выдаче
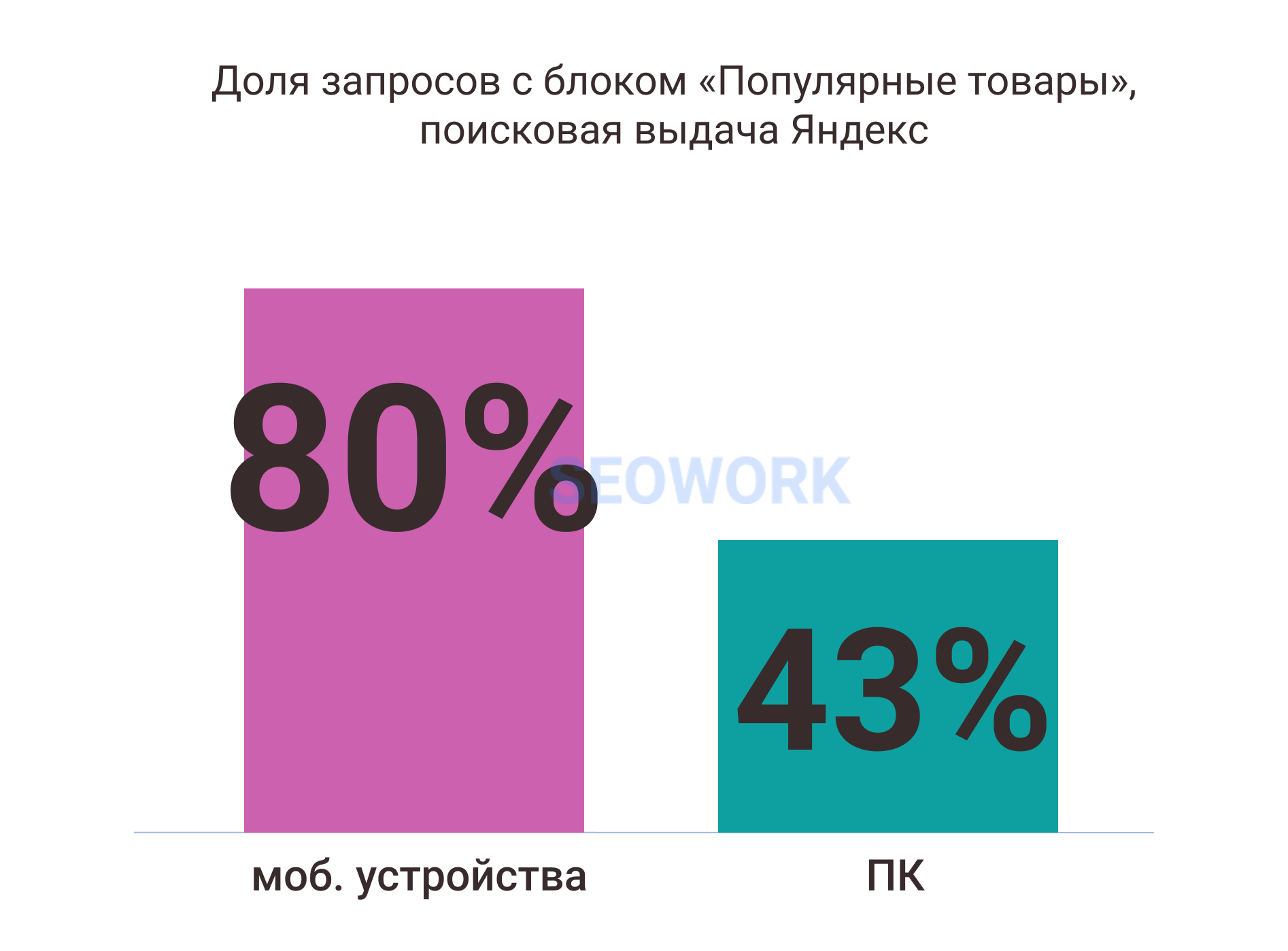
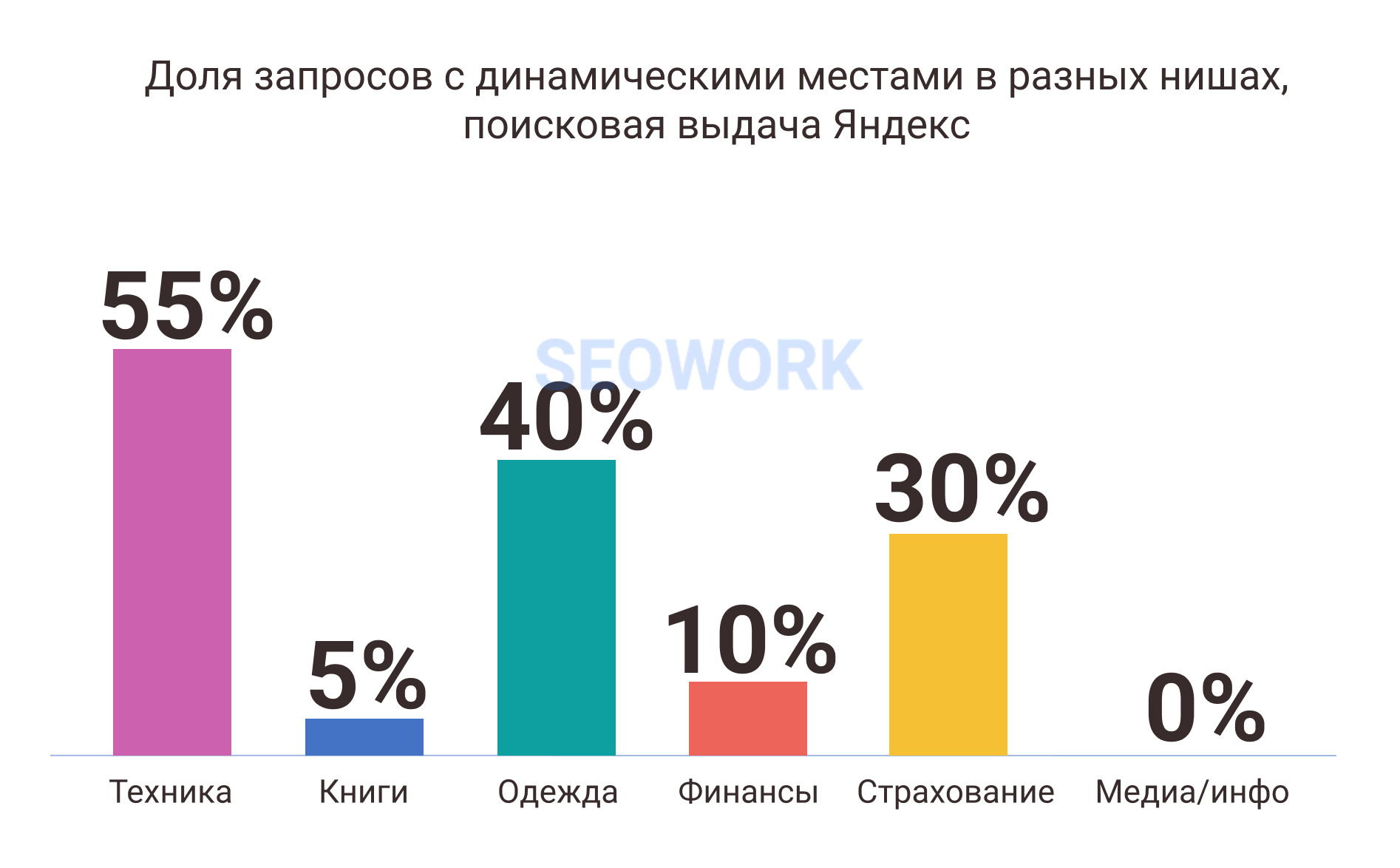
- также в нише e-com все активней проявляются Динамические места – новый рекламный формат, который отвлекает внимание пользователей
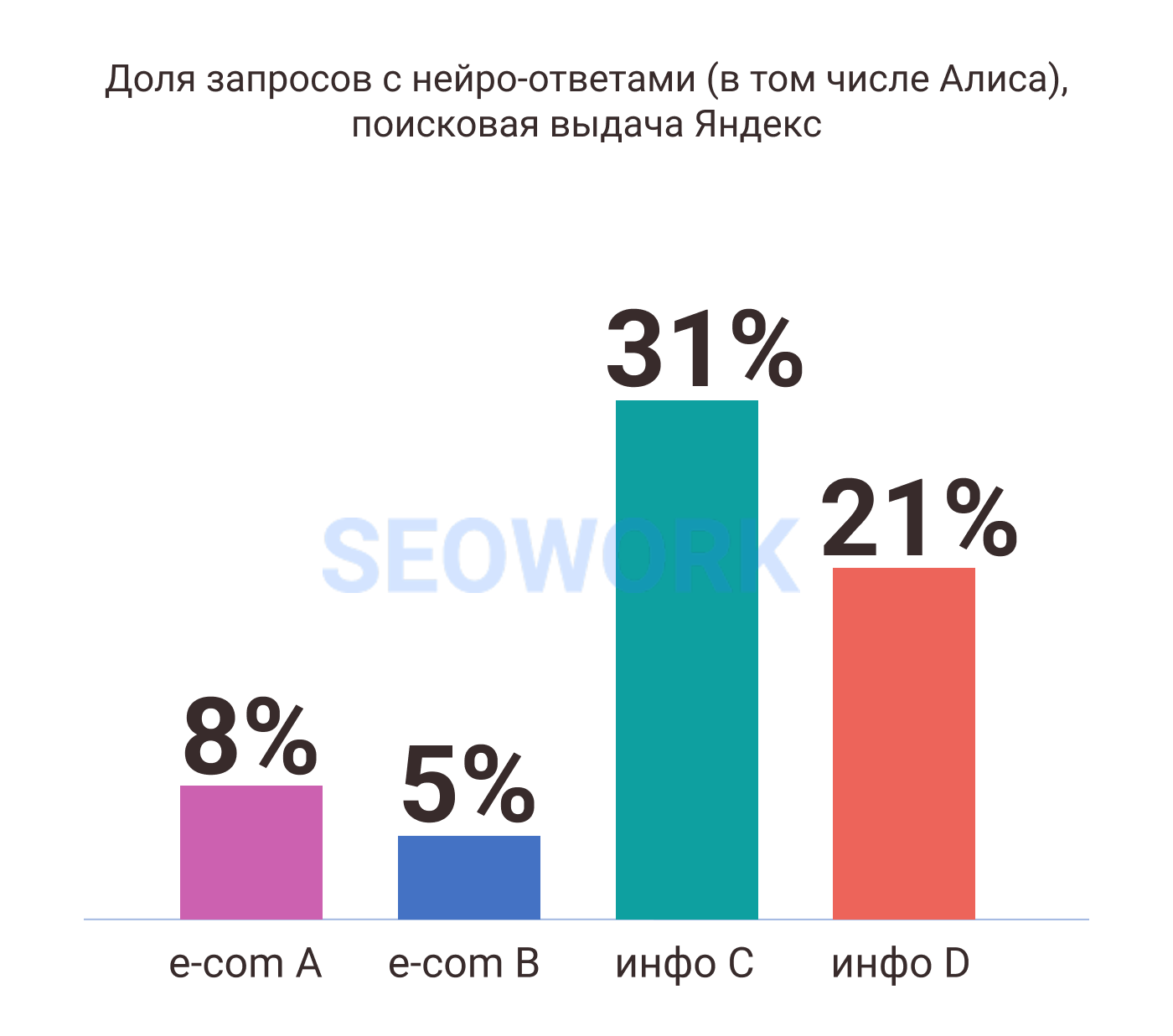
- все чаще появляются в выдаче блоки с ИИ ответами от Алисы, особенно это заметно по информационным запросам и инфо-проектам
Не учитывая все перечисленные элементы, XML даёт достаточно упрощенную аналитику, всё менее отражающую реальную картину и конкурентов за внимание пользователей.
Search API HTML
Search API HTML – HTML-файл с результатами поиска по заданному запросу, идентичный HTML-странице соответствующей поисковой выдачи на главной странице Яндекс Поиска в режиме инкогнито.
Результат запроса в HTML-формате содержит больше данных, чем результат аналогичного запроса в XML-формате: результат в HTML-формате включает в себя рекламу, спец. элементы показа (например, товарные блоки), ответы Алисы, а также другие элементы, которые могут появиться в поисковой выдаче. HTML-формат ответа регулярно обновляется вместе с форматом поисковой выдачи Яндекса.
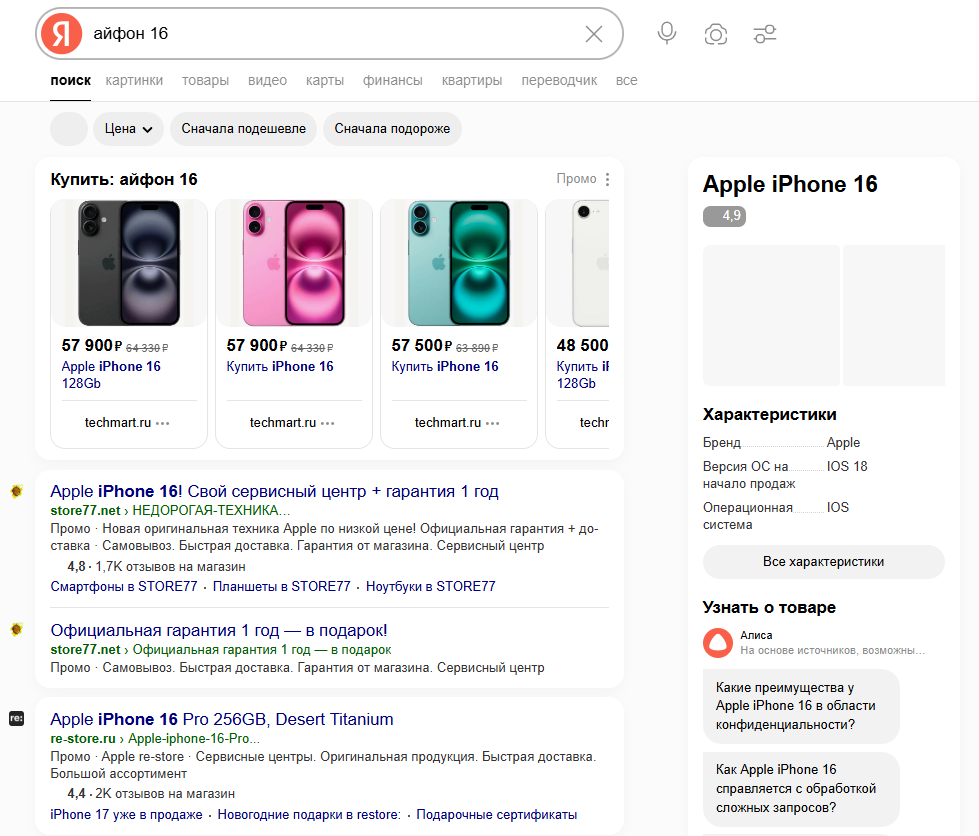
Очевидно, HTML позволяет получать более полные данные. В этом легко убедиться самостоятельно – сопоставить данные о выдаче, полученные в Search API в формате XML и HTML, для одного и того же запроса, в одном и том же регионе, в одно время.
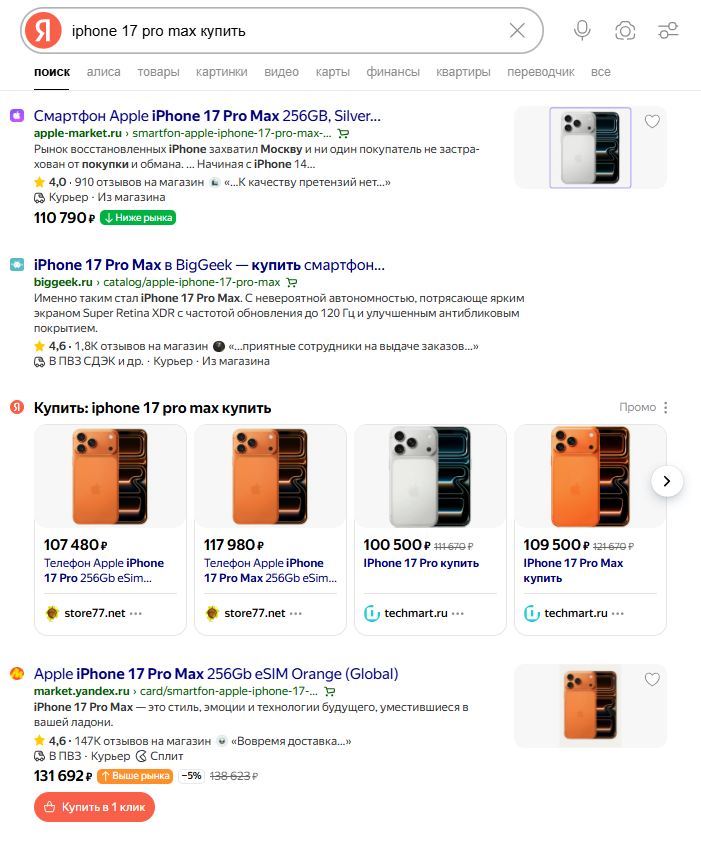
Например, сравним данные о выдаче для запроса «iphone 17 pro max купить», гео – Москва, данные по выдаче на десктопе, время сбора — 20.12.2025, 09:20
Пользователь видит такую выдачу
Упорядочим в XML и HTML элементы выдачи в том порядке, в котором их видит пользователь, и сравним наличие данных о них в HTML и XML.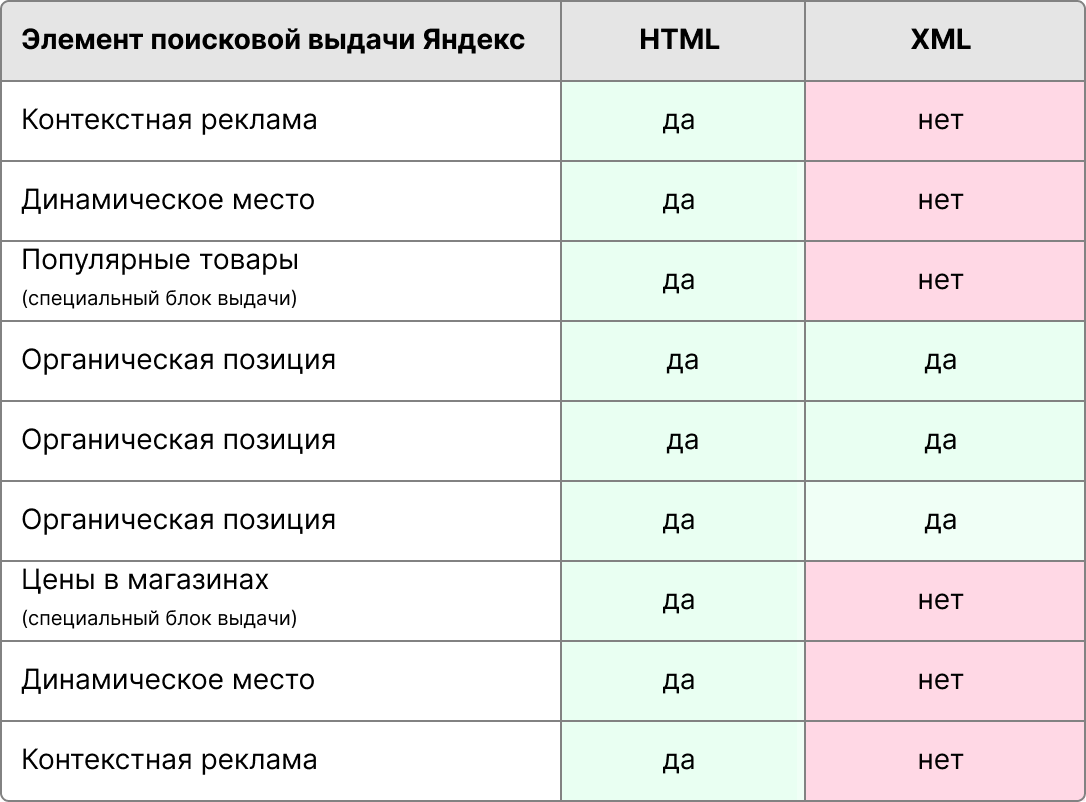
Как видим, XML отображает только органические позиции, тогда как HTML дает более полную картину и понимание о реальной конкуренции за внимание пользователя, а в нашем случае – покупателя, ведь в запросе явно звучало намерением о покупке.
Почему же подавляющее большинство SEO-сервисов использует как источник данных XML, а не HTML? Дело в том, что HTML требует от команды сильной экспертизы по работе с данными и более мощной инфраструктуры. Как итог – работа с HTML существенно дороже и сложнее, чем работа с XML
Как устроен сбор данных в SEOWORK?
Как мы выяснили, полнота данных XML ограничена, а парсинг живой выдачи при новых усиленных механизмах защиты Яндекса перестал быть рациональным решением – он нестабилен, дорог и плохо масштабируется. Именно поэтому осенью 2025 года мы приняли стратегическое решение перейти на получение данных через Yandex Search API в формате HTML.
Полнота и качество данных — ключевая ценность для нас
Мы применяем и вслед за меняющейся выдачей совершенствуем собственные технологии полного разбора HTML — со всеми блоками и элементами. Технически это более сложный путь, но именно он в итоге обеспечивает пользователям платформы
- возможность анализировать всю поисковую выдачу, а не только позиции
- понимание реальной картины поиска, а не её упрощённой версии
- готовность к тому, как поиcк будет выглядеть в 2026 году
Подводя итоги
В 2025 году Yandex Search API фактически закрепился как стандарт получения данных для SEO-сервисов.
При этом выбор формата внутри API напрямую влияет на качество аналитики. XML остаётся простым и доступным решением, но отражает лишь часть поисковой картины. В SEOWORK мы сделали ставку на HTML-формат, как источник данных, который позволяет работать с полной версией выдачи — со всеми её элементами и изменениями, и обеспечивает более точное понимание поиска.

