
В SEO успех часто оценивают через позиции сайта в выдаче по отдельным запросам. Данные о позициях можно получать из разных источников, только вот многие команды отмечают, что эти данные нередко отличаются. Почему так происходит, где более точные данные и кому верить?
Мы решили разобраться и изучить особенности основных методов получения данных о позициях в Яндекс.
Источники данных о позициях в Яндекс
Существует три основных источника данных о позициях сайта в Яндекс: живая выдача, Яндекс.Вебмастер и Яндекс Search API. У каждого свои преимущества и недостатки.
Яндекс.Вебмастер
Официальный источник данных от Яндекс.
- Преимущество: стабильность данных.
- Недостатки: доступна информация только по своему сайту – нет информации о конкурентах и специальных элементах выдачи (нулевая позиция, блок Нейро), недельная задержка в отображении данных
Яндекс Search API
Популярный метод, используемый многими SEO-сервисами.
- Преимущество: данные более актуальны, чем в Яндекс.Вебмастере – нет недельной задержки, информация о конкурентном окружении.
- Недостаток: ограниченные сведения о спец. элементах выдачи (в Яндекс Search API есть HTML-формат получения ответа, где якобы есть все спец элементы, но данные ограничены ТОП10), данные Search API берутся из индексного слоя Яндекса – эти данные похожи на те, которые видит живой пользователь в инкогнито, но всё же имеют отличия.
Живая выдача
Выдача в реальном времени – самый динамичный метод получения данных.
- Преимущества: наиболее полные и актуальные данные, информация о спец элементах выдачи и конкурентном окружении.
- Недостаток: незначительные краткосрочные колебания позиций.
Источники данных о позициях в Яндекс: кто точней?
Насколько отличаются данные этих источников? Чтобы ответить на этот вопрос мы запустили ряд экспериментов со сбором данных для нескольких выборок с различным числом запросов – от 600 до 15 000.
Дополнительно внутри выборок мы выделяли группы высоко-, средне- и низкочастотных запросов (далее – ВЧ, СЧ, НЧ), чтобы понять, насколько результаты по ним могут различаться.
Для всех выборок в течение двух недель мы собирали данные о позициях из различных источников, в том числе различными методами получения живой выдачи:
- метод №1 – xmlriver, публичный источник, часто используется оптимизаторами
- метод №2 – источник данных, разработанный для SEOWORK
- метод №3 – популярный на рынке непубличный источник, используется SEO-сервисами
Точность данных каждого источника мы оценивали через волатильность.
Волатильность — изменения позиций сайта в выдаче за определенный период времени.
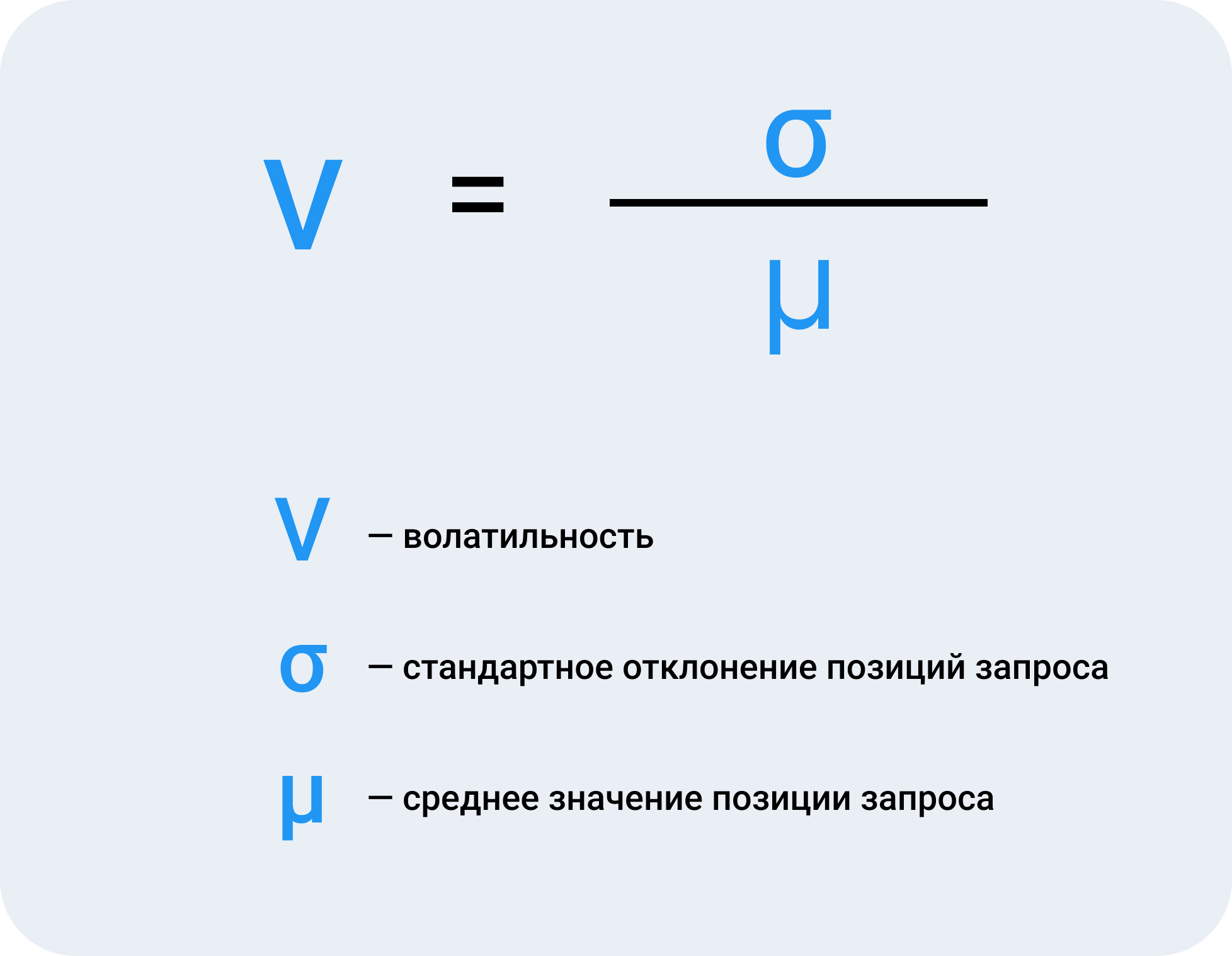
В нашем эксперименте значения волатильности мы агрегировали как среднее по всей выборке запросов в течении 2-х недель.
Мы сравнили волатильность каждого источника в каждом отдельном эксперименте — во всех экспериментах выводы оказались одинаковы!
Проиллюстрируем их на примере сбора данных о позициях для 673 запросов.
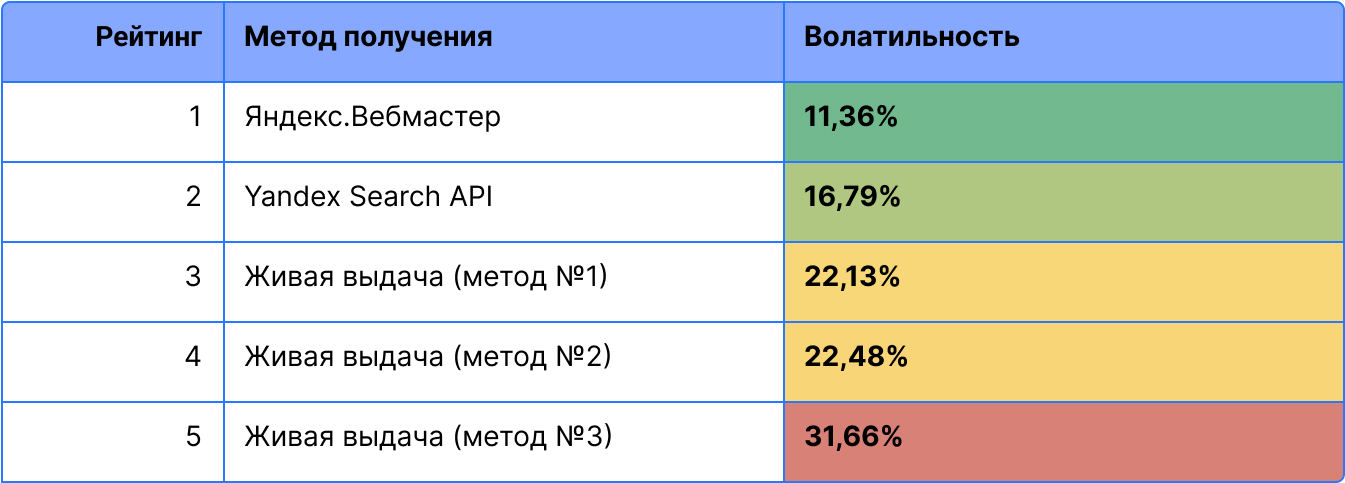
Наименьшую волатильность показал Яндекс.Вебмастер, наибольшую – живая выдача.
Мы отдельно рассчитали волатильность для высоко-, средне- и низкочастотных запросов. Расчеты показывают, что волатильность характерна для всех запросов, независимо от их частотности. При этом волатильность Яндекс.Вебмастера может отличаться, в зависимости от частотности запросов.
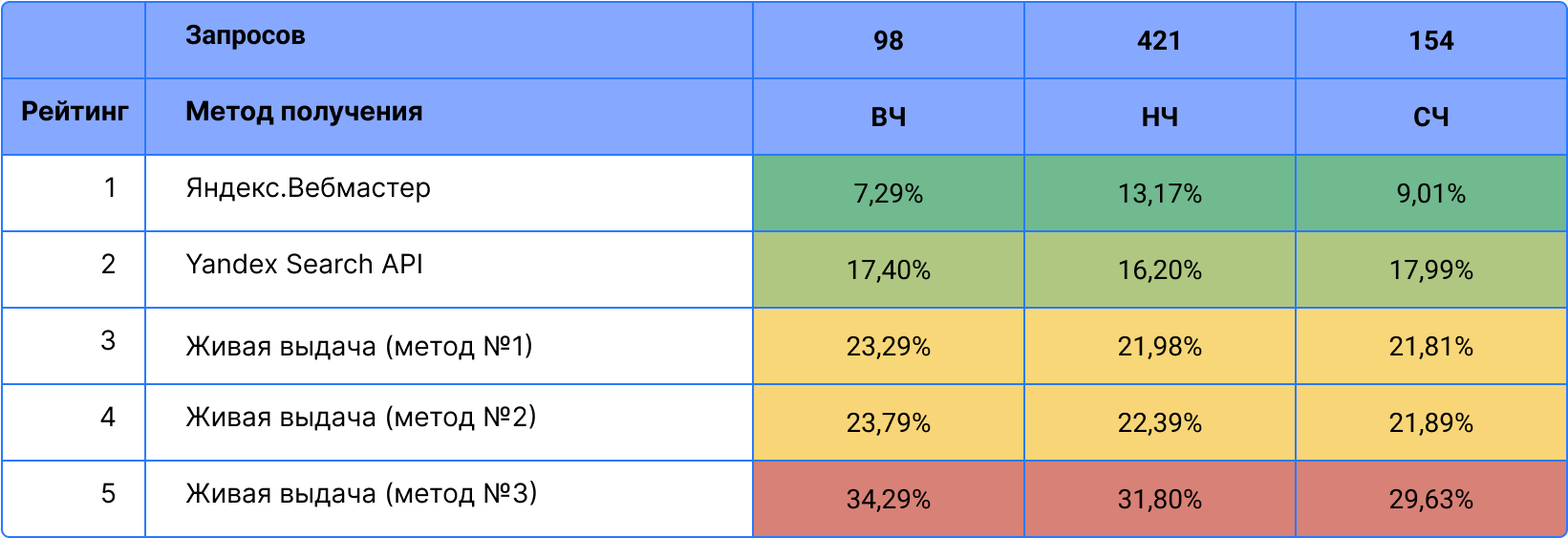
Дополнительно мы сравнили число запросов, по которым сайт попадает в ТОП выдачи. Независимо от частотности запроса, разница в ТОП3 выдачи между всеми источниками оказалась намного выше, чем среди более низких позиций. Живая выдача при это дает самую оптимистичную картину.

Все методы сбора данных имеют определенную степень волатильности.
- Яндекс.Вебмастер показывает наименьшую волатильность
- Яндекс Search API показывает среднюю степень волатильности
- живая выдача наиболее волатильна (22-31% в зависимости от метода сбора).
Аналогичные результаты показал эксперимент со сбором данных для 15 000 запросов.
Данные о позициях собирались также в течении 2-х недель по трем разным источникам. Выборка также была поделена на 3 группы запросов, в зависимости от их частотности.
Расчеты волатильности подтвердил: наименьшая волатильность у Яндекс.Вебмастер, за ним следует Яндекс Search API и наиболее волатильна живая выдача.
Число запросов в выдаче будет значимо различаться у разных источников для ТОП3 выдачи и не так существенно проявляться для более низких позиций. При этом наибольшее число запросов в выдаче будет показывать живая выдача. В качестве примера привели ниже сравнение Яндекс.Вебмастер и Яндекс Search API с живой выдачей, собранной по методу №2 – уникальному методу сбора данных SEOWORK.
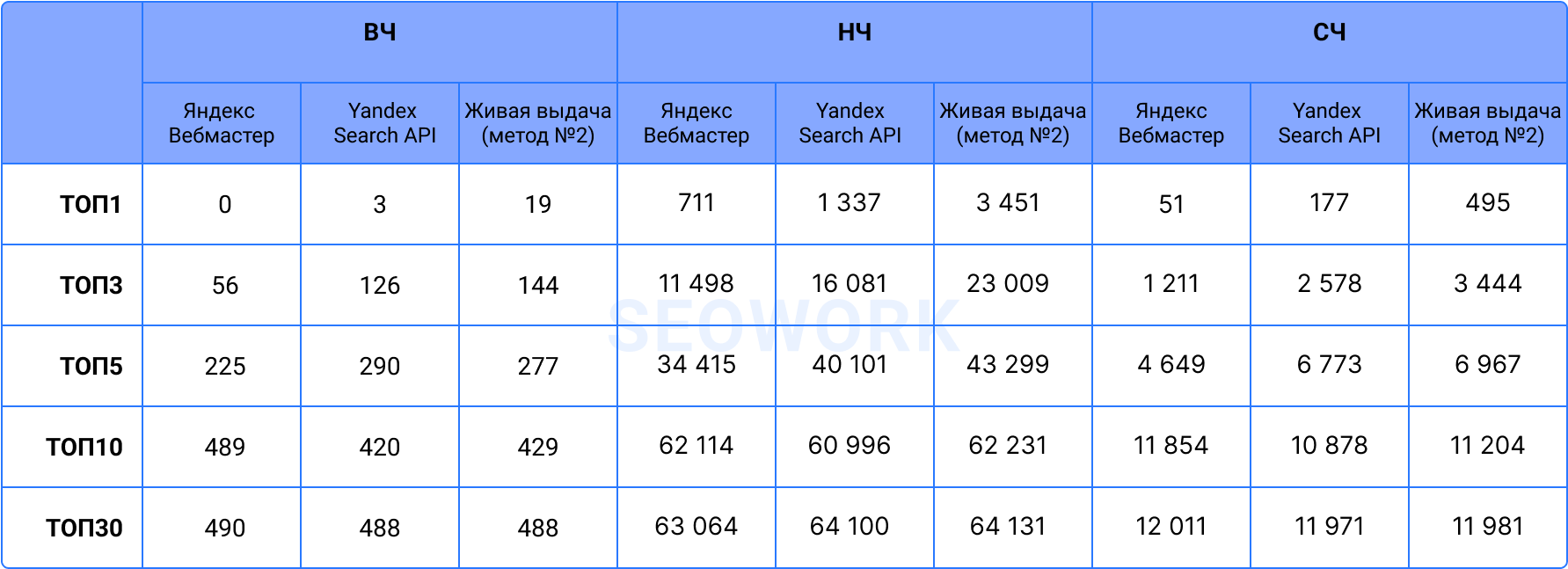
Волатильность в действии
Все вы замечали, что при многократном запросе одного и того же поискового запроса примерно в одно и тоже время, позиции сайта могут варьировать. Буквально это означает, что если 50 пользователей в один момент вбивают в поисковик один и тот же запрос в одном и том же регионе, то результаты их поиска с какой-то вероятностью будут различаться.
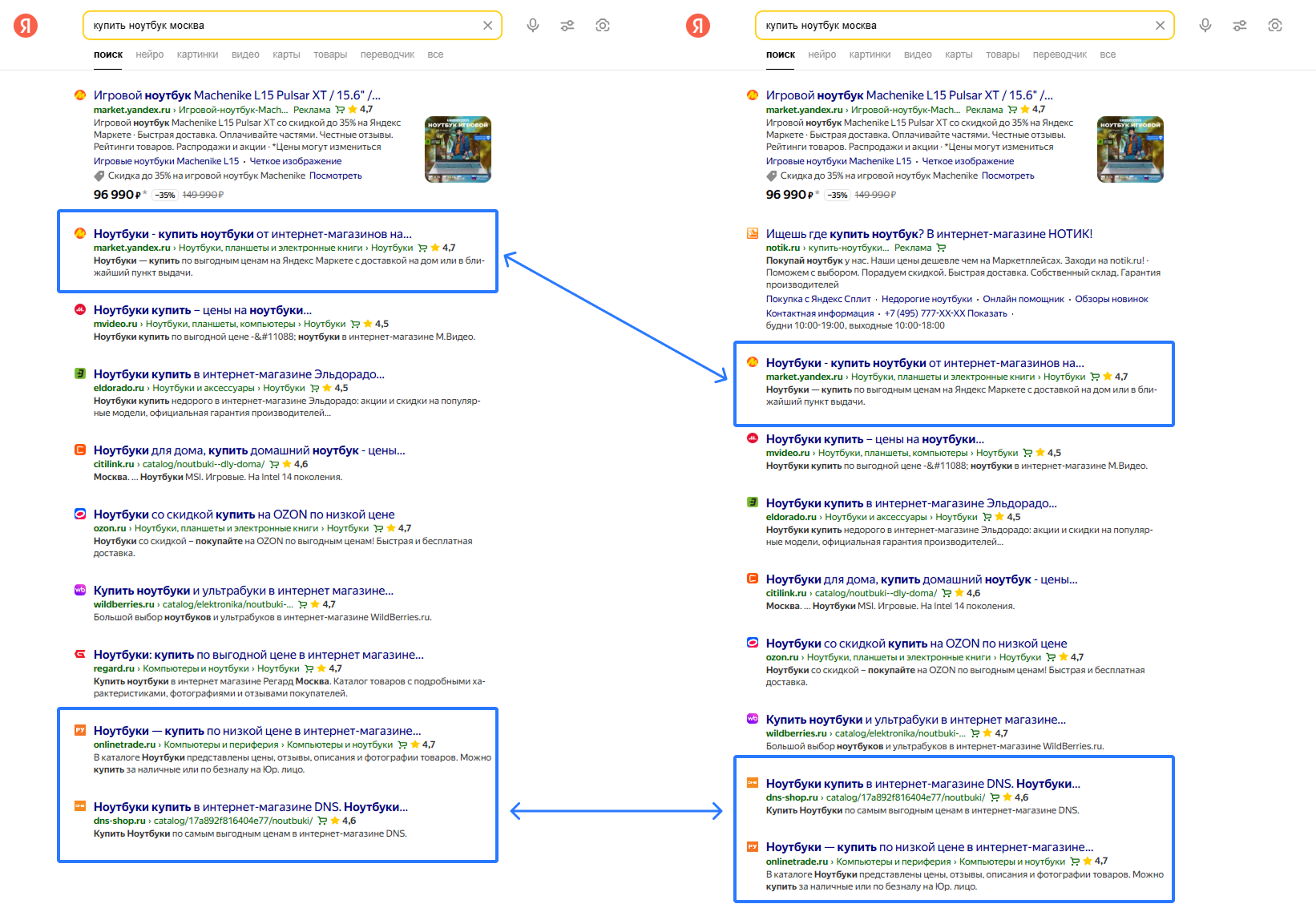
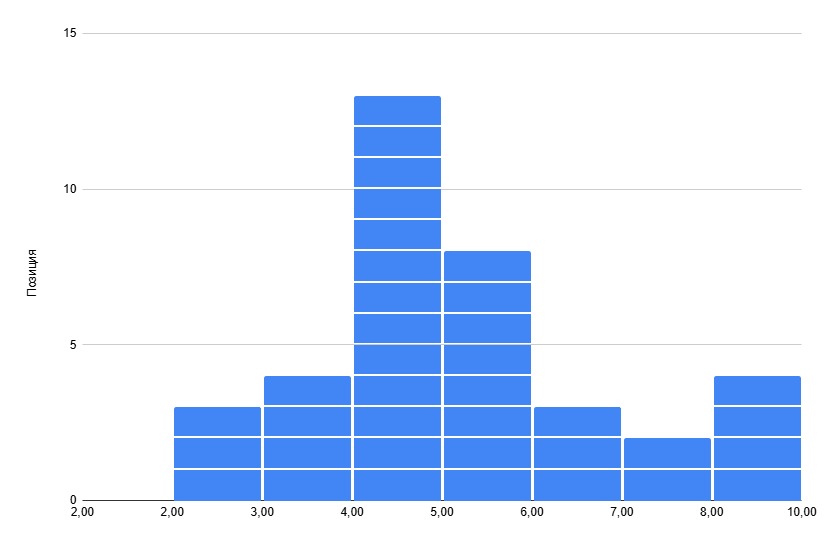
В нашем эксперименте позиция одного сайта колебалась от 2-ой до 10-ой – это говорит о наличии волатильности в течении дня. При этом самое частое значение (мода) было 4 – это видно и на гистограмме ниже, а средняя позиция – 4,76
Что это значит для SEO-специалистов?
- Не стоит паниковать из-за колебаний позиций по отдельным запросам в короткий период.

- Сфокусироваться на трендах и агрегированных метриках, а не на отдельных позициях.
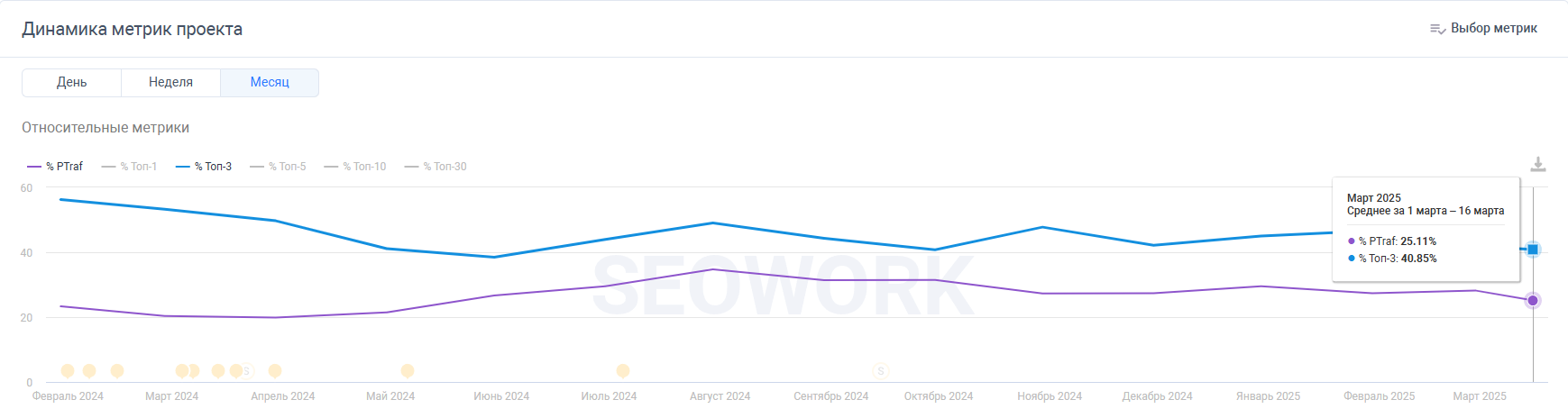
- Анализировать совокупность метрик в разрезе поисковых систем и основных вертикалей, от спроса до поискового трафика

Наглядно показать, как поисковый трафик помогает бизнесу зарабатывать, позволяет SEO-воронка, на которой основные SEO-показатели увязаны с транзакциями и выручкой. Как такой отчет построить рассказываем в отдельной статье.
Снижаем волатильность
На конкретных примерах мы убедились, что волатильности не избежать. Волатильность есть у всех источников данных о позициях и у всех SEO-сервисов. Можно ли снизить волатильность? Да!
Команда SEOWORK разработала и применяет ряд уникальных механизмов сбора и проверки данных из разных источников. Все это позволяет нам снизить волатильность и повысить точность данных в платформе.
Рассмотрим некоторые такие механизмы:
- Сравнение с предыдущими результатами
Когда мы получаем данные о позициях сайта, наша система автоматически сравнивает их с предыдущими результатами. Если обнаруживается значительное отклонение, система повторно проверяет позиции, чтобы убедиться в их точности.
- Индивидуальный подход к перепроверкам
Мы применяем разные стратегии перепроверки в зависимости от двух факторов:
– частотность запроса
– близость к ТОП1 (насколько высоко запрос находился в предыдущей проверке).
Например, для самых высокочастотных запросов проекта мы можем использовать гибридную стратегию. Это значит, что при пересборе позиций данные о «колдунщиках» мы возьмем из живой выдачи, а позиции — из Яндекс Search API.
Для запросов с низкой частотностью мы используем данные только из живой выдачи, перепроверяя её несколько раз для повышения точности.
Чем ближе запрос был к первой позиции в предыдущей проверке, тем большего внимания заслуживает даже небольшое отклонение. Например, если сайт был на 2-м месте, а теперь на 5-м, это будет сигналом для перепроверки. Но если сайт был на 20-м месте, а теперь на 26-м, такое отклонение может быть признано незначительным и дополнительная проверка не потребуется.
Тенденции развития поисковой выдачи
Поисковые системы постоянно эволюционируют.
В начале года Яндекс запустил блок Нейро, который может существенно повлиять на традиционное понимание позиций, так как этот блок занимает больше места в выдаче и начинает показываться всё чаще, сдвигая органическую выдачу всё ниже.
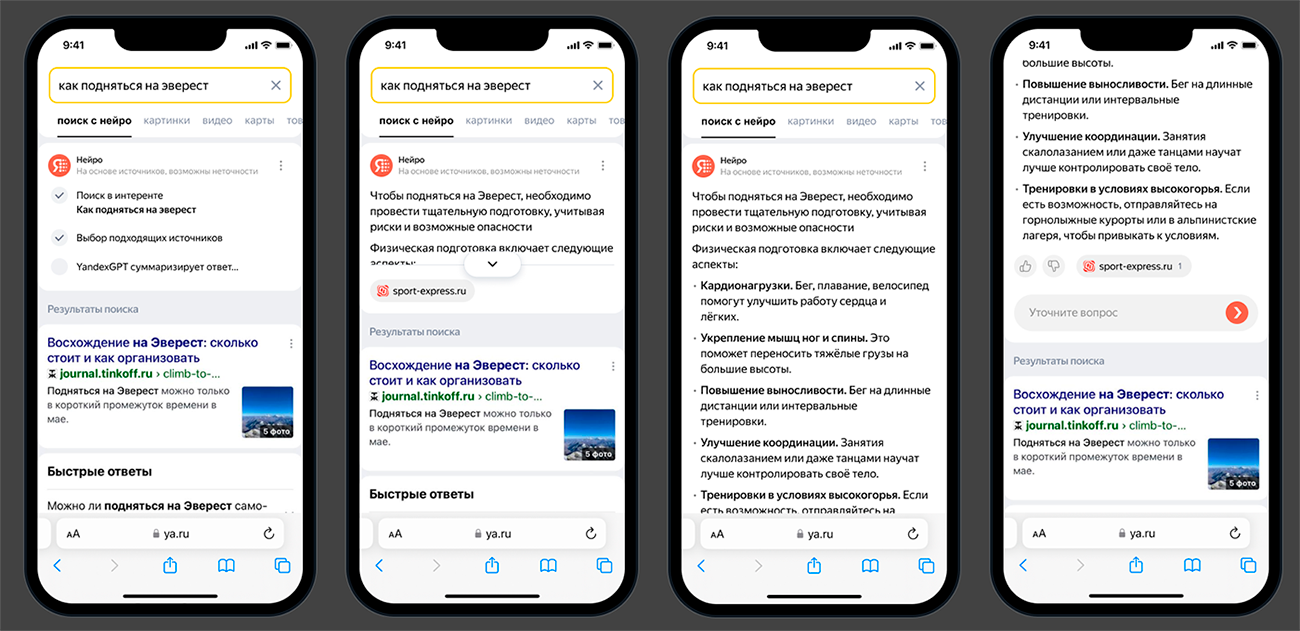
Также в начале года в Яндекс появился динамический блок контекстной рекламы, который лаконично встраивается в органические результаты поиска.
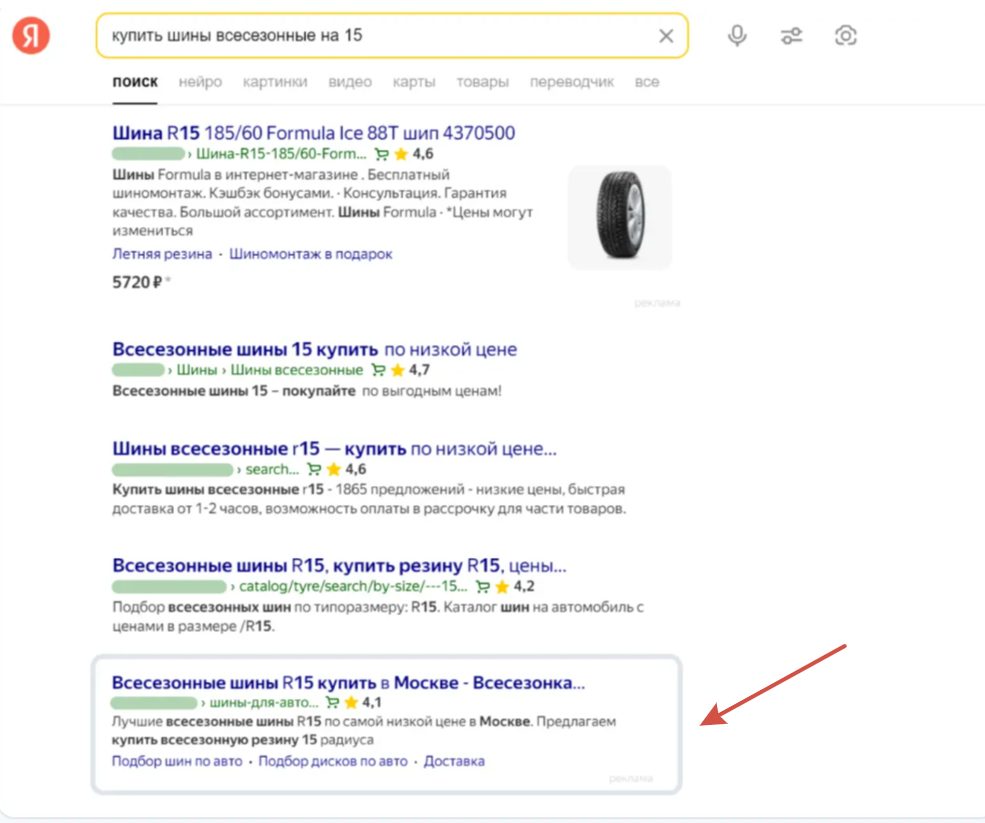
Все эти изменения явно говорят о необходимости переходить от мониторинга позиций к комплексному анализу метрик проекта.
SEO – это марафон, а не спринт. Долгосрочные тренды и фокус на глубокую аналитику может оказаться важнее замеров позиций.

