Как находить точки роста в крупном екомерс, где любое слово может стать ключевиком? Какие инструменты продвижения выбрать и как настроить с нуля систему аналитики? Опытом поделился Head of SEO в Printbar Евгений Горбунов. Рассказываем про его доклад на прошедшем Optimization 2022. Поехали!
Специфика Printbar: коротко о главном
Основные моменты, связанные с еком-проектом и влиющие на продвижение:
- семантика бесконечная (любое слово может стать ключом для продвижения);
- ниша – мерч, одежда и все с рисунками / принтами;
- в ТОП-10 входит или проект, или конкурент (и партнеры);
- физических товаров нет, а по факту их миллион.
Проблемы проекта:
Из специфики проекта вытекают проблемы продвижения:
- наличие авторских прав и лицензий (к примеру, герои фильмов, авторы крылатых выражений, известные персонажи и т.д.);
- отсутствие семантики и историчности;
- инструментов для аналитики и поиска точек роста мало;
- отчеты Яндекс.Метрики, Google и вебмастеров неточные;
- отсутствие классической системы формирования семантики (когда все работы выполняет SEO-специалист): в данном кейсе в формировании семантики участвуют дизайнеры и смежные специалисты.
Проблемы с SEO:
Вот с каким «диагнозом» сайт достался SEO-специалисту:
- снижение объема трафика в 2 раза;
- необходимость выполнения технических работ (мета, логи и т.д.);
- запросы 18+;
- структура плоская;
- дублирование названий принтов, приводящие к повторам карточек на первом листинге;
- SEO-админка слабая;
- canonical на трафиковых страницах.
Задачи, поставленные перед SEO-специалистом:
Задачи, поставленные перед специалистом:
- рост органического трафика в 2-3 раза;
- настройка процессов продвижения и аналитики (трафик, продажи, семантика).
В команде профессионалы в области ИТ и крутые дизайнеры. Сотрудников смело можно назвать сильной стороной проекта. Слабые стороны – отсутствие работы над брендом, минимальная аналитика про проекту, нет стратегии развития и роста. Большую часть процессов необходимо было выстраивать с нуля.
Систематизация
На проекте многие процессы работали «как есть» без стратегии. На первых этапах собрали семантику и начали работать над критическими проблемами. После того, как сделали это, решились на переезд каталога, чтобы уйти от плоской структуры.
На всех этапах работы использовали инструменты SEOWORK (ниже будет крутой кейс, как использовали DATAFORCE от SEOWORK и каких результатов добились).
Поиск инструментов для работы
Классические Яндекс.Метрика и Google Analytics для крупного еком не подходили, т.к. не работали с большими объемами данных. Пользоваться Я.Метрикой и GA было невозможно по несколькими причинам:
- зависания при попытке загрузить большое количество данных;
- невозможность провести качественную аналитику из-за отсутствия фильтров по сегментам.
В результате решено было отказаться от Яндекс Метрики и Google Analytics в пользу Google Data Studio и SEOWORK.
В GDS сформировали 3 основных отчета:
- трафик;
- поиск по сайту;
- Google Search Console (создавали больше для дизайнеров).
Пользоваться GDS удобно, т.к. дашборды простые, но при этом можно использовать дополнительные инструменты:
- работа с большими массивами данных без подвисаний;
- фильтр точек входа;
- фиксация просадок и пикового роста.
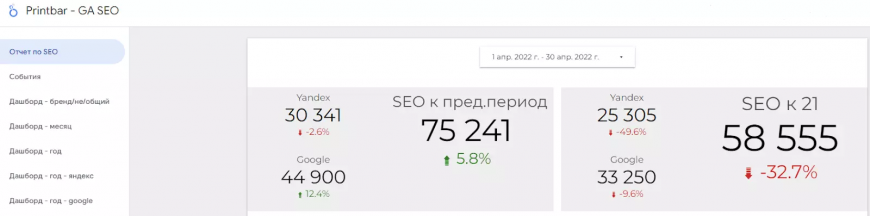
SEO-специалисты обращались к GDS каждую неделю, чтобы отслеживать динамику и сравнивать метрики 7 дней к предыдущим 7 дням (не каждый инструмент позволяет делать столь качественную и скрупулезную аналитику).
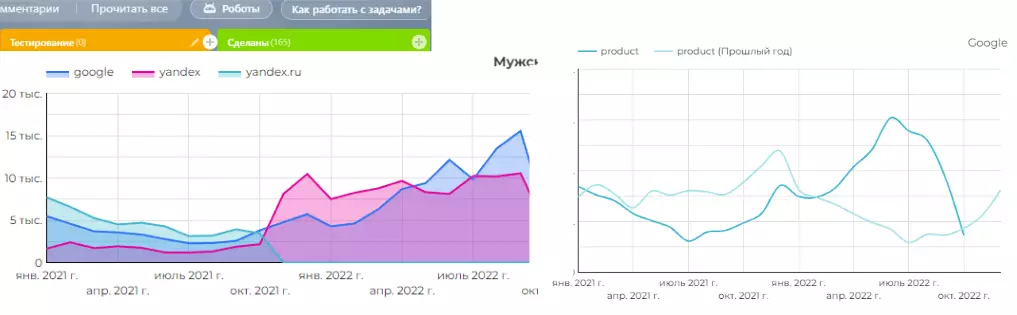
Пример отчета по SEO в реальном екомерс-проекте
Семантика 18+
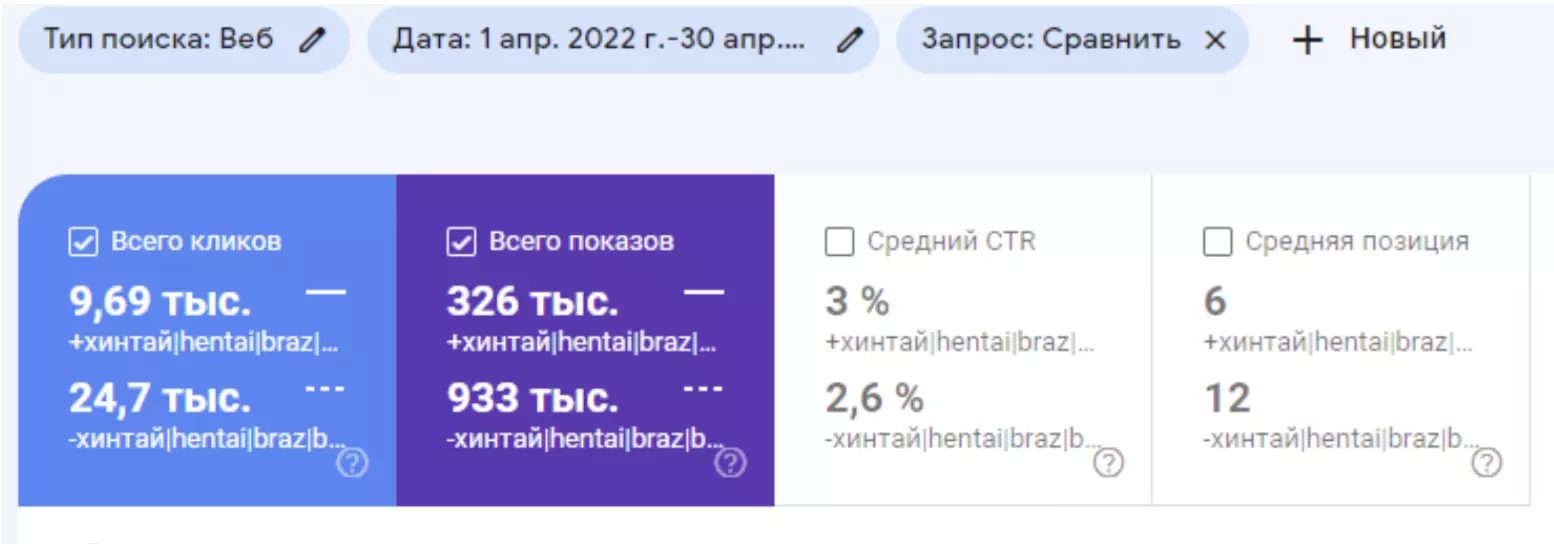
Кейс Printbar оказался интересным опытом с точки зрения семантики. Около 10 тыс. запросов клиента приходились на тематику «18+». Отказаться от нее – это значит потерять большое количество потенциальных покупателей. Продолжать продвижение «как есть» – это значит столкнуться с ограничениями поисковых систем.
Решено было оптимизировать работу с ключами 18+. Задача – разделить детские и взрослые категории. Все принты 18+ попали во взрослую.
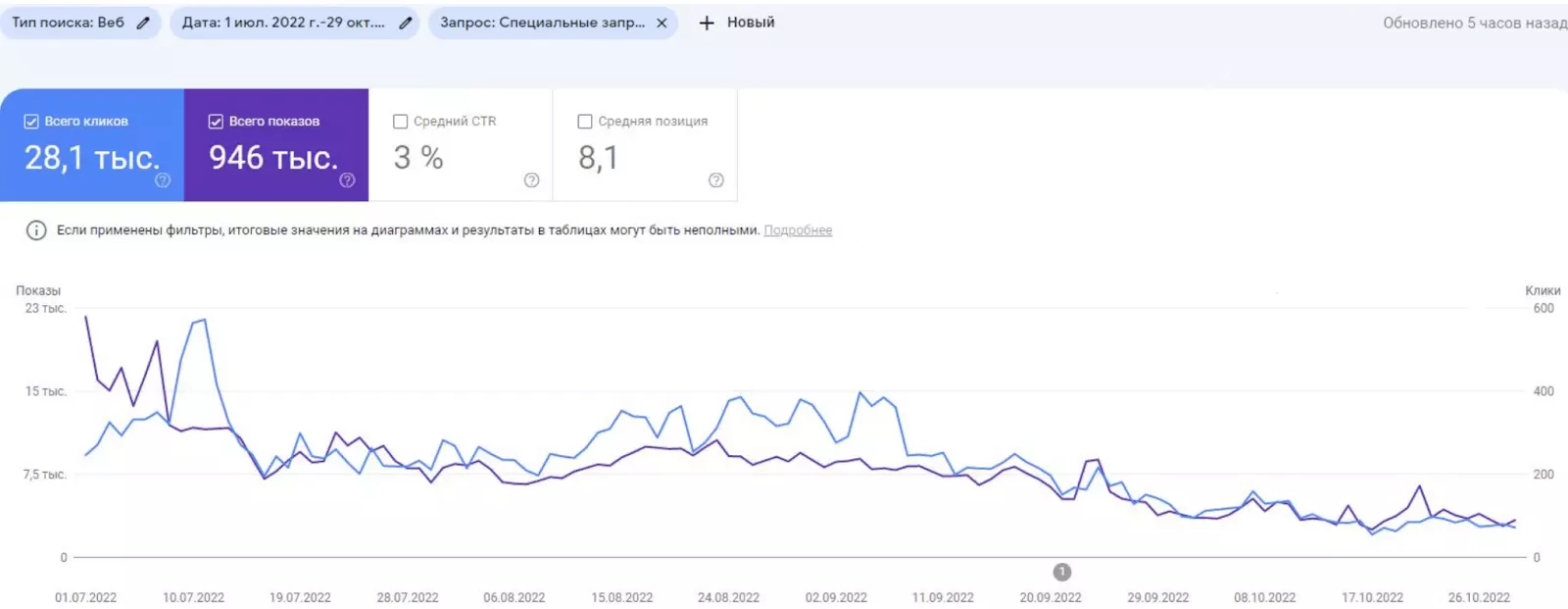
Итоги работы с семантикой 18+ на проекте Printbar
SEO-анализ и набор инструментов для специалиста
Выше уже писали, что для работы выбрали Google Data Studio как наиболее подходящий инструмент с отчетами и фильтрами.
В дополнение к GDS взяли Power BI. Данный инструмент подошел для анализа органики.
Также решено было использовать для аналитики на проекте:
- Serpstat (позиции);
- Searchlab (тексты);
- Labrika (проверка вхождения ключей).
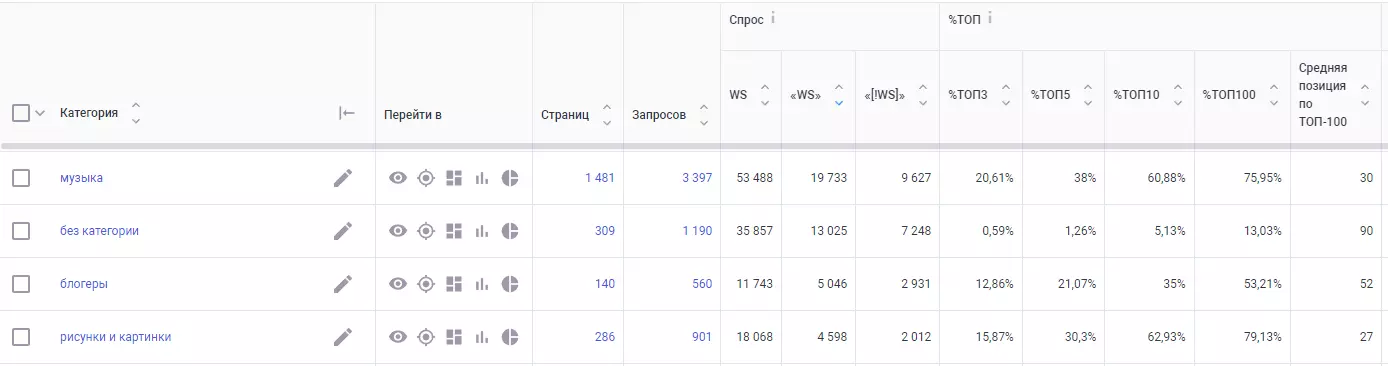
Модуль SEOWORK
Больше всего полезной и важной для аналитика информации дает модуль SEOWORK. На момент составления кейса в него было загружено 30 000+ запросов. Для визуализации настроена сегментация.
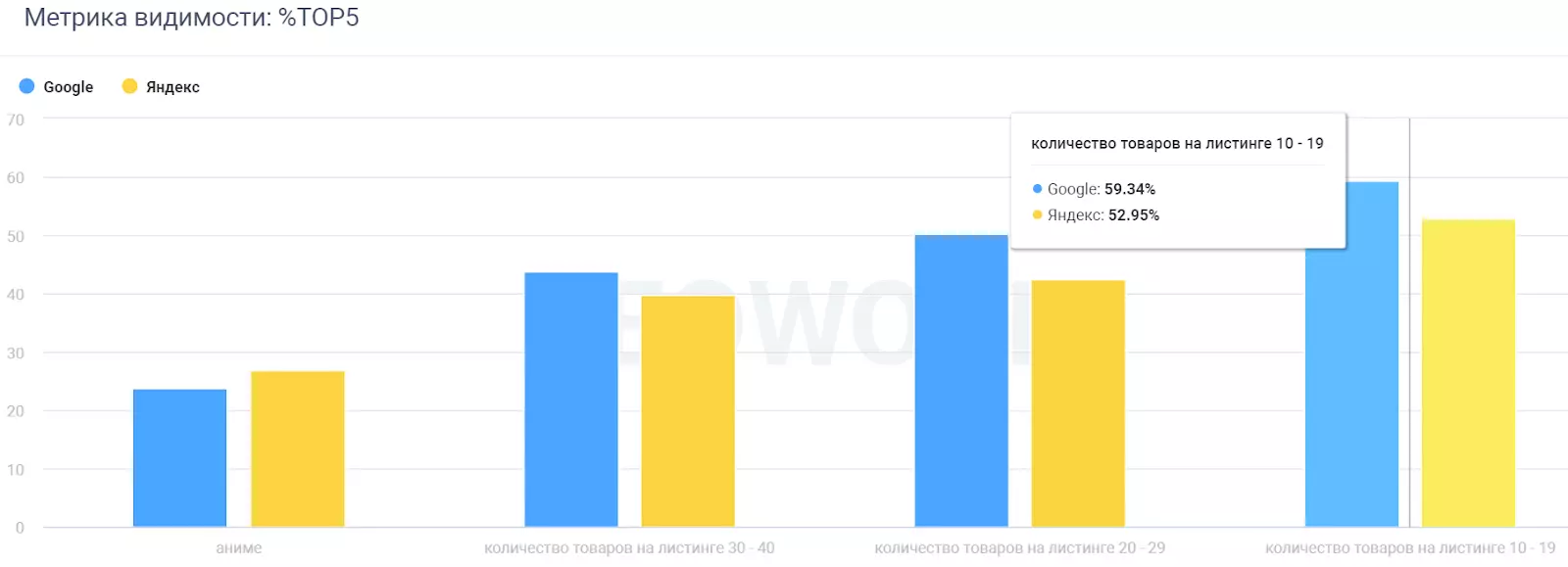
Метрики видимости %ТОП5 для поисковых систем Яндекс и Гугл
Кейс выше используется для того, чтобы понять, сколько товаров должно быть на листинге (что лучше конвертит: 10-19 штук. 20-29 или 30-40).
Существуют и другие наглядные примеры, как использовать модули SEOWORK.
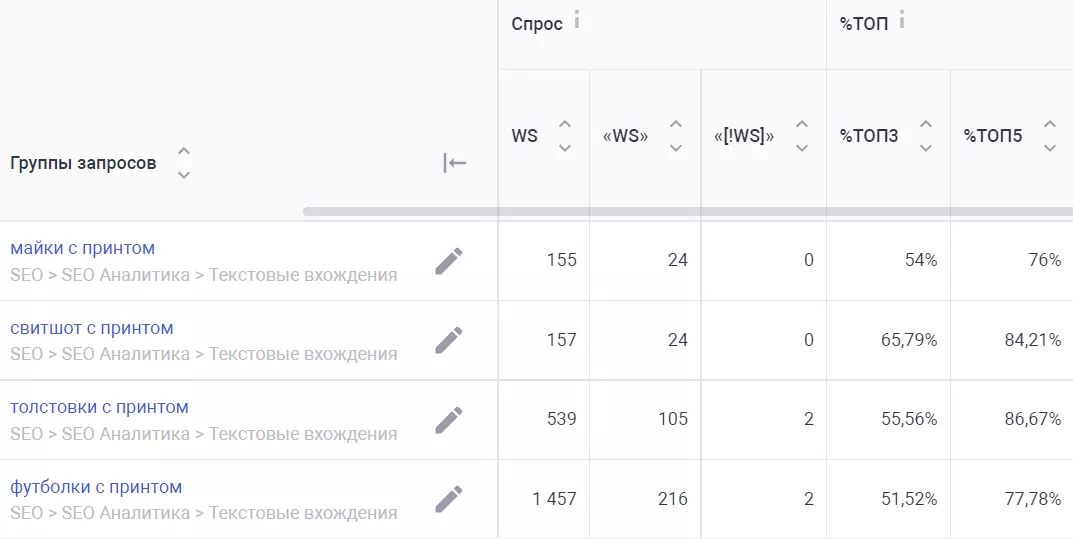
У нас есть вхождения «с принтом». Дальше при помощи SEOWORK оцениваем спрос и видимость, на основе чего принимаем решение, добавлять ли ключ в title.
Само собой, это только некоторые примеры, как используются инструменты SEOWORK в реальных екомерс-проектах. На практике же вариантов гораздо больше: все зависит от специфики проекта и от подхода SEO-специалиста.
В результате работы с SEOWORK мы получаем отчеты, которые дальше смогут использоваться специалистами SEO, маркетинга и дизайна. Т.е. именно от SEO-специалиста поступает информация по поводу того, какие интересы у пользователей (на что есть спрос). На основе этого дизайнер может отрисовать новый принт.
Аналитика с использованием инструментов SEOWORK дает и еще одно важное преимущество: специалист видит резкие изменения категорий (рост или падение). Это дает возможность реагировать и работать на опережение без серьезных потерь трафика.
В SEO-админке работать с коллекциями стало проще:
- API для фидов
- импорт и экспорт в пару кликов;
- блоки перелинковки;
- шаблонизаторы для мета-тегов и текстов (листинги и карточки).
Эти нюансы особенно важны для екомерс с 500+ тыс. страниц. В противном случае в точках входа появляется много мусора.
Хорошо. Возникает закономерная гипотеза: сделать 1 млн запросов, создать 1 млн страниц и получить профит. Увы, так не работает. Давайте разберемся почему.
Семантика и сложности работы с ней на примере Printbar
Где искать?
Семантическое ядро Printbar – все подряд. Это могут быть мемы, крылатые фразы из фильмов, шутки, города – в общем, вариантов масса. осложняется все это тем, что постоянно появляются новые мемы и герои: вордстат просто не успевает за реальностью. Но не только в этом дело. Многие принты защищены лицензиями и авторскими правами (особенно касается популярных героев – Бэтмена, Спайдермена, Железного Человека и т.д.).
Как результат – трафик проекта распределяется наполовину: 50% приходится на листинги и 50% – на карточки.
Чтобы работать с семантическим ядром, принимаем следующие условия:
- название карточки важно;
- присутствие карточки в индексе обязательно;
- нерелевантность карточки (в основном для Гугла).
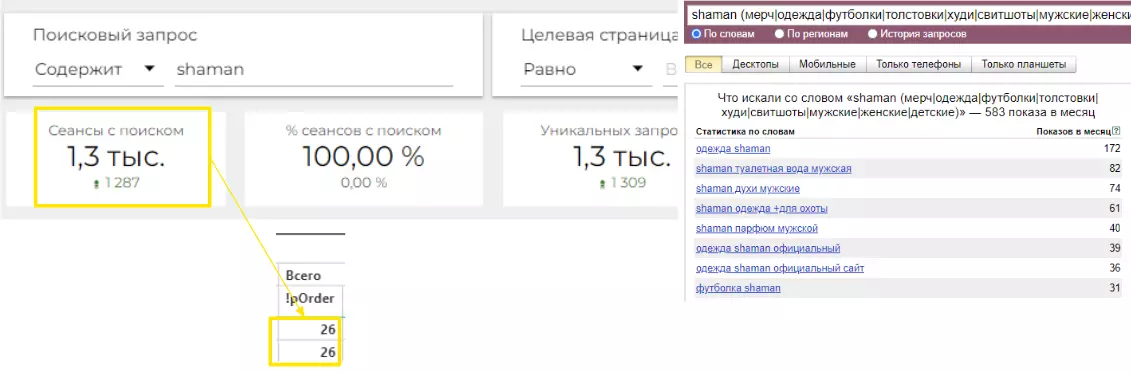
Пример отчета из GDS и Вордстата
Wordstat в рамках проекта использовали, но осторожно (в сочетании с другими инструментами). Причина проста: Вордстат не всегда понимает интент запроса и не всегда способен отразить то, что происходит в реальности (прямо здесь и сейчас). Для примера выше взяли запрос «shaman одежда» с мерчем исполнителя.
Благодаря отчетам Google Data Studio по результатам внутреннего поиска видны только релевантные запросы. Эти данные очень помогают отделам дизайна и продвижения: когда они видят реальный спрос. На основе этого на сайте появляется новая карточка, а отдел дизайна отрисовывает принт. Т.е. эти процессы удалось практически автоматизировать, чтобы идеально попадать в пиковый спрос и удовлетворять запросы покупателей. Один Вордстат с этой задачей бы не справился.
Поиск семантики для Printbar требует отдельного пояснения. Кроме классических сервисов keyso, moab, букварикс или overlead и парсинга выдачи, необходимо «держать руку на пульсе» и следить за «выстреливающими хитами». Поэтому дополнительно для поиска семантики решено использовать:
- внутренний поиск, вебмастера – основной инструмент;
- сайты по кино, фильмам, сериалам, книгам, вселенным, играм;
- мемы и картинки, а также многое другое.
Единичные запросы нас не интересуют. В работу попадают только те, спрос на которые достигает определенных значений.
Как собирать семантическое ядро для продвижения?
В связи с особенностями проекта решено было выбрать нестандартную стратегию сбора и кластеризации семантики.
Обычно специалисты создают массив данных, а затем делят его на группы. У Printbar удалось настроить систему, когда это происходит «на ходу».
Коллекции собираются через скрейпер, дальше создается элементарная сцепка по одному из параметров (к примеру, возраст или тематика). В результате получается что-то вроде:
- футболки 30 лет;
- 2Pac футболки.
Дальше парсится, проверяется частность и получается семантика для работы. Подход Printbar можно использовать и в других нишах.
План сбора семантики (на примере Printbar)
Чтобы получить максимально полное семантическое ядро, используем пошаговую инструкцию:
- Генерирование. Берем слово (к примеру, «природа»), собираем весь словарь и дальше нормализуем при помощи специальных сервисов. Можно использовать py7.ru/tools/norm/ или аналогичные.
- Комбинирование. Сочетаем полученные слова с тематическими и коммерческими масками.
- Парсинг. Берем подсказки поисковой выдачи, а также данные из специализированных сервисов (Вордстат, мутаген, Оверлид, Вордкипер и другие). Также нужно спарсить релевантные страницы (они могут быть, а ТОПа нет).
- Сбор информации с инфосайтов. Нужно спарсить сведения по тематикам музыки, аниме, кино, сериалов и игр. Основные поля, которые интересуют аналитика, – герой (персонаж), актер, автор, режиссер.
Метрики
Работа с семантикой в рамках проекта достаточно сложная и трудозатратная. В обработке больше 3 млн фраз, которые нужно каким-то образом анализировать и систематизировать. Основные метрики, которые используются на проекте:
- частотность;
- показы / клики из Вебмастера;
- показы / кол-во запросов из внутреннего поиска;
- показы из контекста;
- данные из ТОП-10 (по некоторым запросам конкурент может быть выше).
Дополнить семантическое ядро помогут специфические данные (в частности, по количеству просмотров кино или числу подписчиков в социальных сетях). Давайте остановимся на последнем более детально.
К примеру, у нас есть музыкальная группа, которая выступает в городе. Вордстат про нее ничего не знает. Но в то же время коллектив активно продвигается в социальной сети Вконтакте, где набрал 40 000 подписчиков. Какой вывод можно сделать из этого? Скорее всего, поклонникам музыкальной группы было бы интересно получить одежду с принтом. У дизайнера появляется задача отрисовать картинку.
Хранение семантического ядра
Общее количество фраз, находящихся в постоянной работе по проекту, – больше 3 млн (+ нулевки и 18+). Появляется закономерный вопрос, связанный с тем, где хранить СЯ.
В нашем случае классическая кластеризация не нужна: все данные хранятся на уровне коллекций.
На данный момент Printbar не нашел сервис для работы с СЯ такого уровня сложности. Приходится создавать собственный.
Вывод по работе с СЯ (на примере Printbar):
- Собирайте идеи для кластеров на информационных сайтах про фильмы, музыку, сериалы, игры.
- Оценивайте продвижение иностранных сайтов схожей тематики.
- Используйте доступ к статистике маркетплейсов (если есть).
- Сочетайте фразы и парсите вглубь.
- Собирайте отчеты в pbi/gds.
- Используйте дополнительные данные для того, чтобы обогатить семантику.
- Берите актуальные сведения из вебмастера.
- Собирайте информацию с поиска по сайту, т.к. она дает сведения о том, что интересует пользователей прямо здесь и прямо сейчас.
Что дал новый подход к СЯ
Итог работы SEO-специалиста на первом этапе (начало сотрудничества) – обновленное СЯ на 21 тыс. запросов. Почти сразу после того, как залили его в сеть, увидели результат – рост трафика к НГ 2022 (даже с учетом сезона). За 3 месяца работы с ИТ-отделом удалось решить большинство вопросов, связанных с техничкой. У проекта появилась стратегия развития.
Как DATAFORCE помогал проекту Print Bar расти, и что из этого вышло
Структура
Проект работал с Power BI, но данных не хватало. Решено было использовать возможности DATAFORCE.
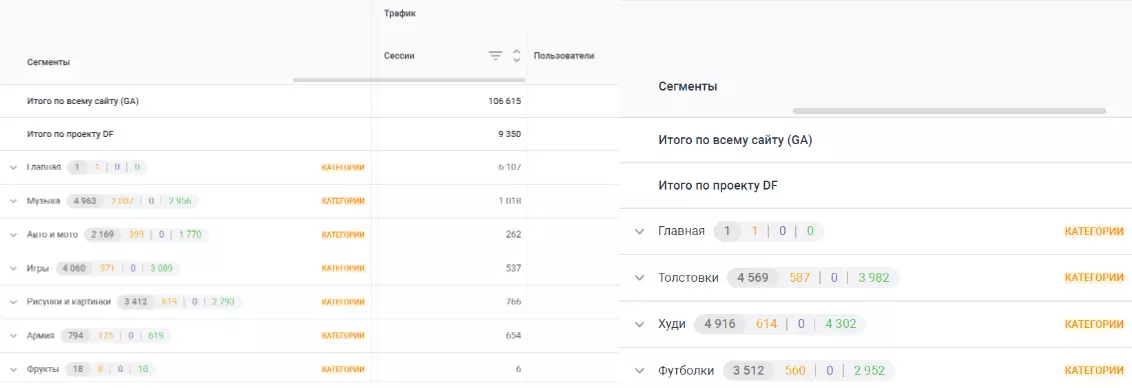
Print Bar работает с двумя основными структурами:
- карточки товаров;
- листинги.
Задача специалиста усложняется тем, что необходимо отслеживать отдельно как «футболки», так и категорию («Музыка», «Авто и мото», а также другие). Именно DATAFORCE позволяет видеть и число листингов, и число карточек.
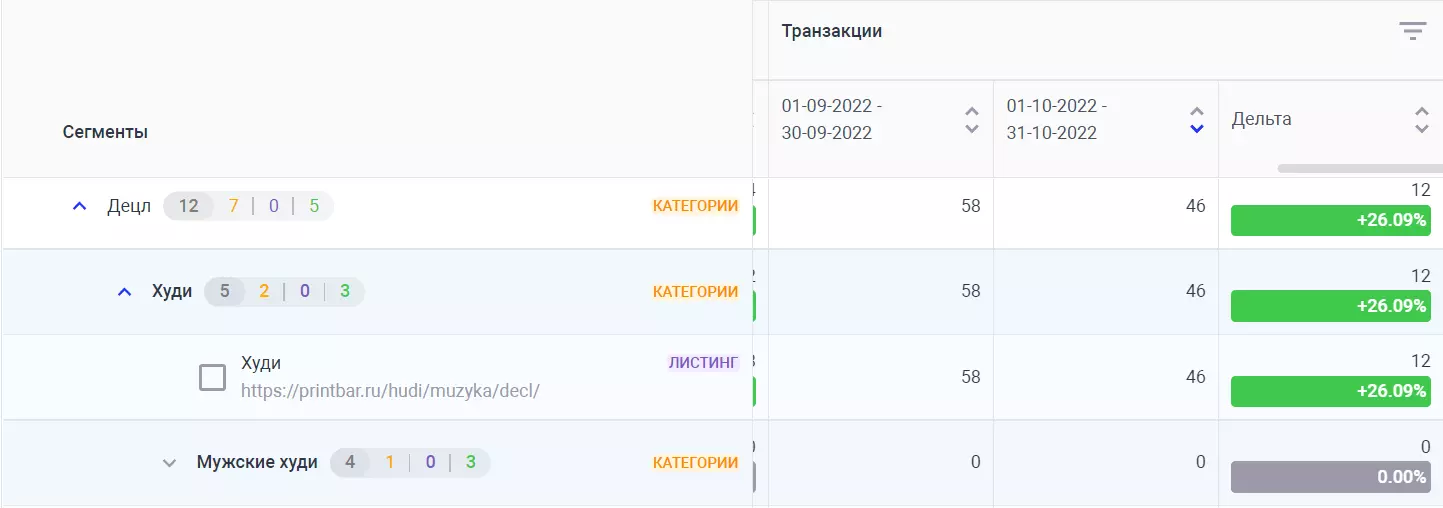
В пару кликов можно увидеть, какие коллекции и на каком продукте покупают больше всего (и наоборот – где наблюдается просадка).
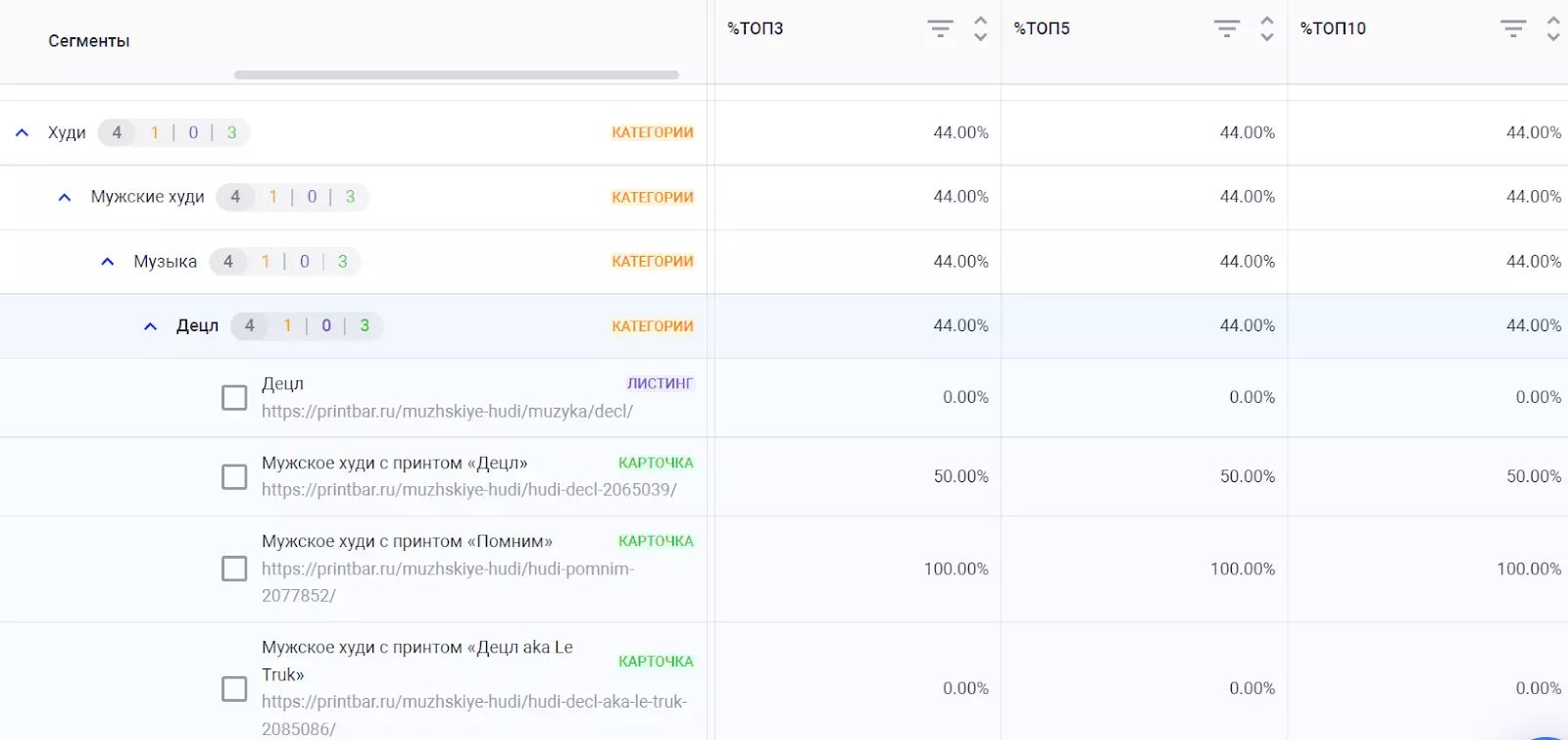
Это позволяет не только управлять продажами, но и работой отдела дизайна.
Карточки товаров
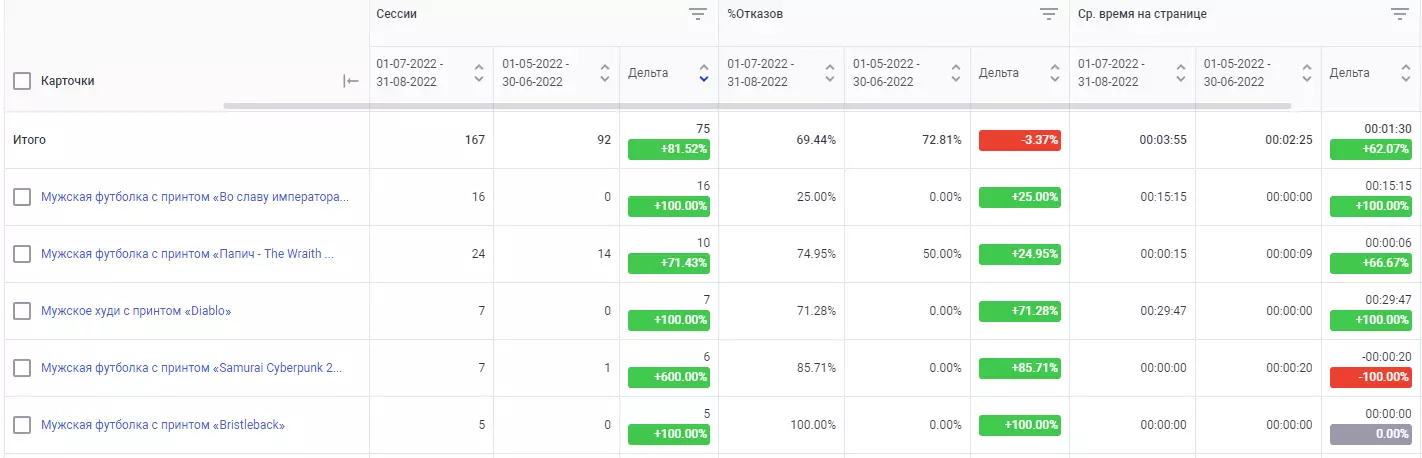
Классический подход в любом екомерс проекте выглядит таким образом: «спарсили названия → наделали тегов → видим рост».
В связи со спецификой проекта в Print Bar пришлось идти другим путем. Нам важен нейминг карточек для продвижения, но здесь появляются проблемы дубликатов. К примеру, на одном листинге у нас может быть 40+ карточек с идентичным названием. Это автоматически влечет проблемы неуникальности и прочие связанные с ними.
Решение проблемы – ренейминг в SEO-админке и мониторинг динамики в DATAFORCE.
Performance
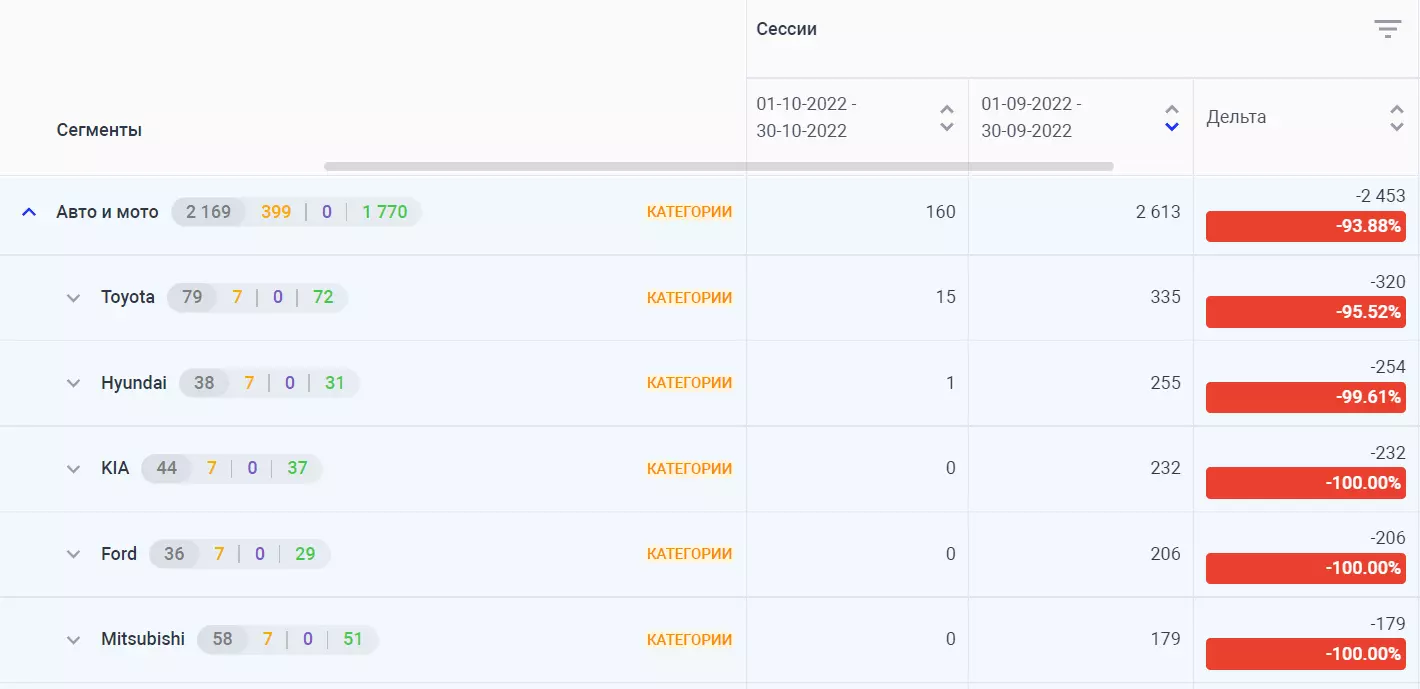
Благодаря настроенной аналитике отделы продвижения и маркетинга в 1 клик получают сведения по товарам: куда идет трафик, где лучше конверт и так далее.
Практика
Старые карточки
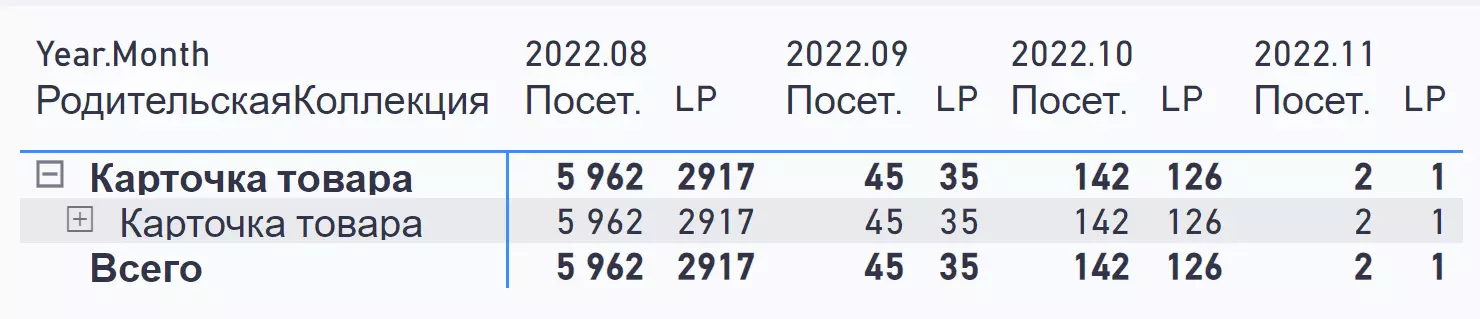
Но любой проект не застрахован от ошибок. При составлении кейсов важно быть честным, рассказать в том числе и о неудачах.
Взяли из GDS старые карточки, которые давали хороший трафик в Гугл, а затем настроили 301 редирект.
Результат – какая-то часть старых карточек переехала на новую структуру. Решения дались непросто: проект потерял около 4,5 тыс. трафика.
Дополненное представление в Yandex
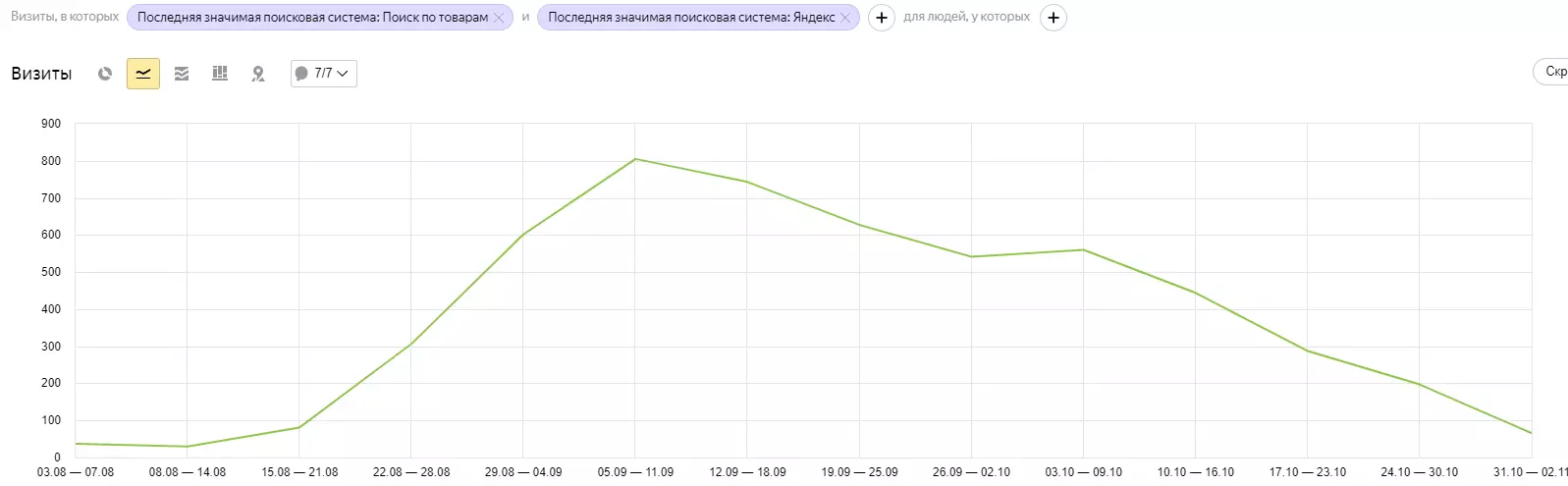
Yandex предложил интересный инструмент, которым решили воспользоваться. Правда, рассчитывать на постоянный трафик не стоит, т.к. все же есть свои особенности.
К примеру, человек делает запрос с принтом, но элемент не отражается в выдаче Яндекса или Google. Дополненное представление позволяет получить определенную долю трафика: если пользователь попадет в нужное название и введет точный запрос, поисковая система покажет ему проект Printbar (даже если он не попал в индекс).
Что сделали и какие результаты получили:
- Подключили API yml.
- В начале сделали 1400 фидов (около 53 млн офферов). Отдельное преимущество дополнения – возможность использовать utm, чтобы отслеживать офферы.
- Уменьшили число фидов в разы. Сейчас их около 250 штук (или 6,6 млн офферов).
- Конверсия посетителей, пришедших благодаря дополненному представлению, в заказ составляет ~3%.

